Filling a 4-year gap here! Did not find time to post itemized yearly overviews, plus
other updates. And that while even more has been happening compared to the past "COVID-years".
Will stick to highlights with a promise to add regular updates.
Below a brief overview of my professional life during 2022-2025.
Highlights of living and working in the Open Source Geospatial and OSGeo(.nl
|.org
)-world,
organized by "Theme".
TL;DR Main 2022-2025 highlights:
- Developed a topographic map of The Netherlands: map5topo
from public (OSM, Kadaster, ...) data-sources.
- Back into OpenStreetMap mapping
and more.
- Part-time living and working in Southern Spain as "Un Nomad Digital", "un teletrabajador".
- Combining the two above: providing OpenStreetMap Workshops in Spain
- Attending FOSS4G and other conferences, providing presentations and workshops
Expanding these highlights.
1. map5topo - rich topographic map of The Netherlands
According to map5.nl
customers we have a product to be proud of.
I say specifically "we" as map5topo
is developed
together with top Dutch digital cartographer Niene Boeijen
.
The map5topo project started in April 2022 and is ongoing since.
So what is the map5topo map about?
In short: it is a digital raster+vector map covering The Netherlands
constructed with Dutch Open Data and deployed via web "mapping" services and apps. That is a mouthful, we'll break this up next.
I often say to friends "...like Google Maps, but prettier and much more detailed".
Try the demo!
We can spend many words here, but if you are curious, try the free demo
.
Constructed with Dutch Open Data
These days, a digital map is created from "source data".
map5topo source data originates from Open Datasets like the Dutch Key Registries, Basisregistraties
: BAG, BRT, BGT, BRK, ..., provided
via Kadaster PDOK
and from OpenStreetMap
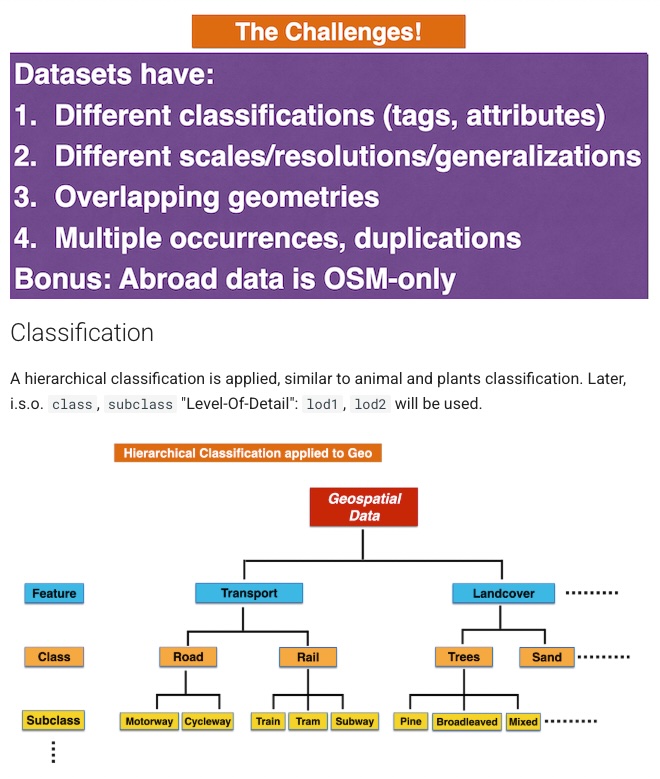
data. Our challenge was to combine all these datasets into one
uniform data model. I think we did a nice effort: take "the-best-of" from each dataset, unification in feature classification, plus
scale-based detailing. See the data design
for details.
Deployed via web mapping services
map5topo is provided commercially by map5.nl via standardized "tiled" web services like OGC WMTS
, but also "XYZ"
(Google/OSM tiles, a.k.a. Web Mercator) tiles. Currently, mainly raster (image) tiles, including "HQ Retina" (double density), but also experimental Vector Tiles.
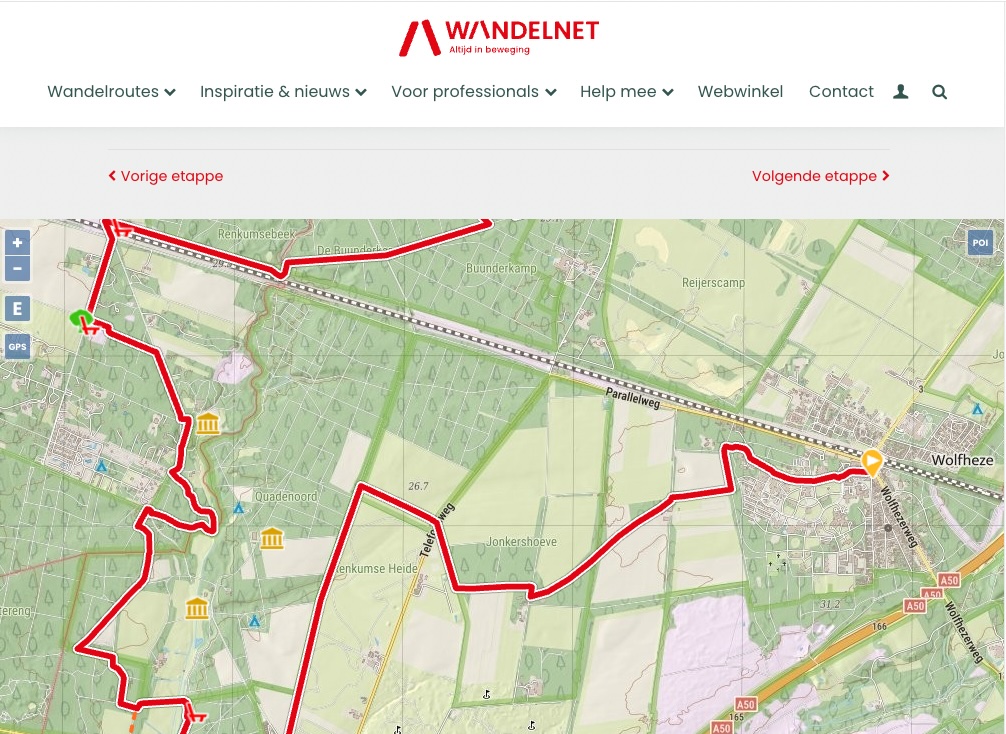
Customers can integrate these maps into their applications. A well-known example is Wandelnet
, a major hiking site in The Netherlands.
There's also various apps we provide
, like the KadViewer
, originally a pilot-viewer for Dutch Kadaster.
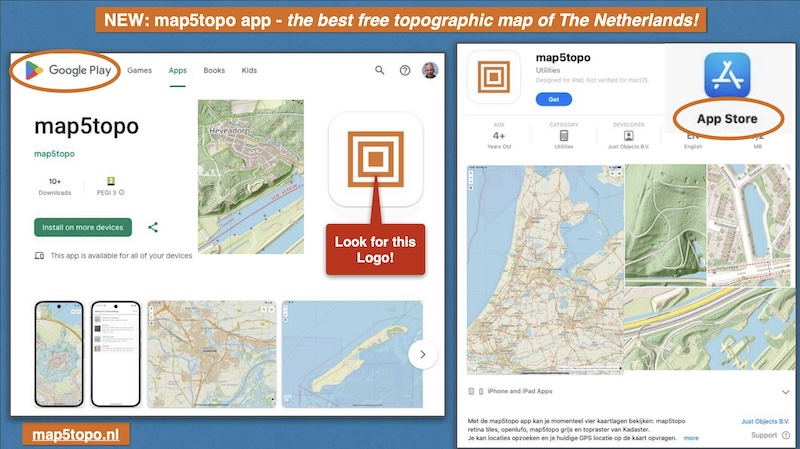
Try it on your phone!
There is a free map5topo app for mobile devices like smartphones and tablets for both Android
and Apple IOS like iPhone.
Developed by Bart Louwers
.
Open Source ?
In the planning. Some repos are already open
. Let me know if you like to co-develop.
2. OpenStreetMap Mapping
I am supposed to be a veteran OSM-mapper, my profile
registered in 2005!
But for many years my mapping efforts were zero.
But in recent years I picked up mapping again.
Regular mapping like hiking paths, and specialized projects like Dutch buildings and addresses with the JOSM BAG Updater
.
Mainly mapping in The Netherlands and Spain (latter see below).
Over 17000 contributions in the last year now!
3. Moving to Southern Spain
After renting homes three winters in the wonderful area of The Alpujarras
(Andalusia),
made the move to buy a small "cortijo", a simple whitewashed house.
What can I say? Landscapes, hiking, the people, the "fiestas", birds & wildlife, the food, are all "estupendo" as is said here.
Working as a digital nomad is easy, internet providers are ok, there's even shared workspaces.
My Spanish language, a must here, is improving, following courses
like Overal Spaans
(recommended!) for B1/B2 level, plus a local conversation class organized by the village.
4. OpenStreetMap Workshops in Spain
Spain is a huge country. Many rural areas like The Alpujarras
are not mapped in great detail.
Though there are still very active mappers in the area. From the beginning I started adding mainly new hiking paths, surveying with GPS via CoMaps
.
I also joined the Spanish OSM Community
(OSM-ES), simply by joining the OSM-ES Telegram group and weekly video-meetups.
In Spain I learned to follow the Catastro Buildings and Addresses import
processes
and I am working on a possible SIOSE Landcover/Landuse import
(WIP).
My gratitude goes out to Héctor Ochoa Ortiz
who introduced me
to the welcoming Spanish OSM community and helped along the way.
After having given a mobile OSM mapping workshop at FOSS4GNL Middelburg 2023
and talking to local people in my village, I got the idea to
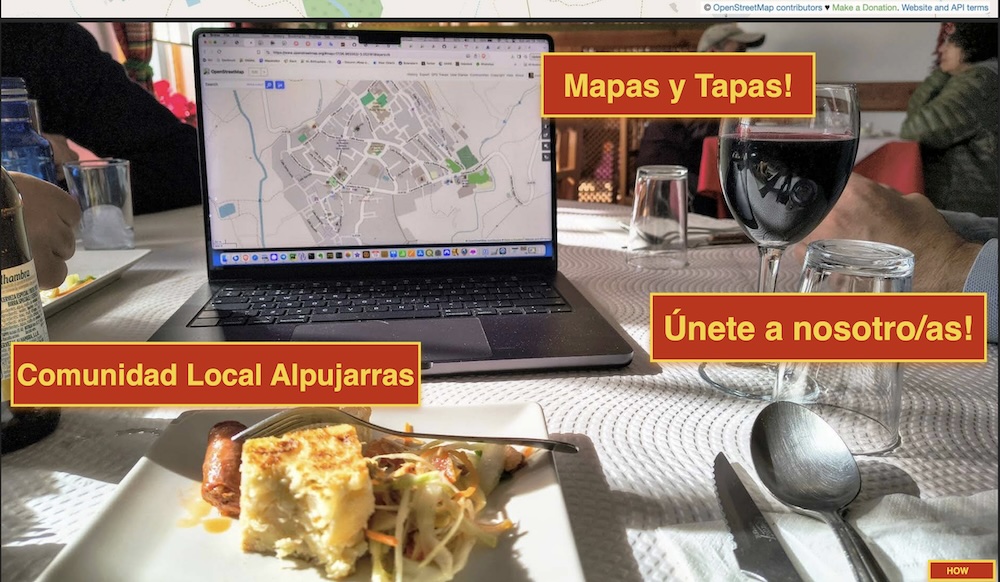
organize OpenStreetMap workshops here. We aptly named our group here "Mapas y Tapas".
The idea being to eventually have Mapping Parties: meet in a bar, map on the streets and "en el campo", reconvene with drinks and the all-abundant "tapas".
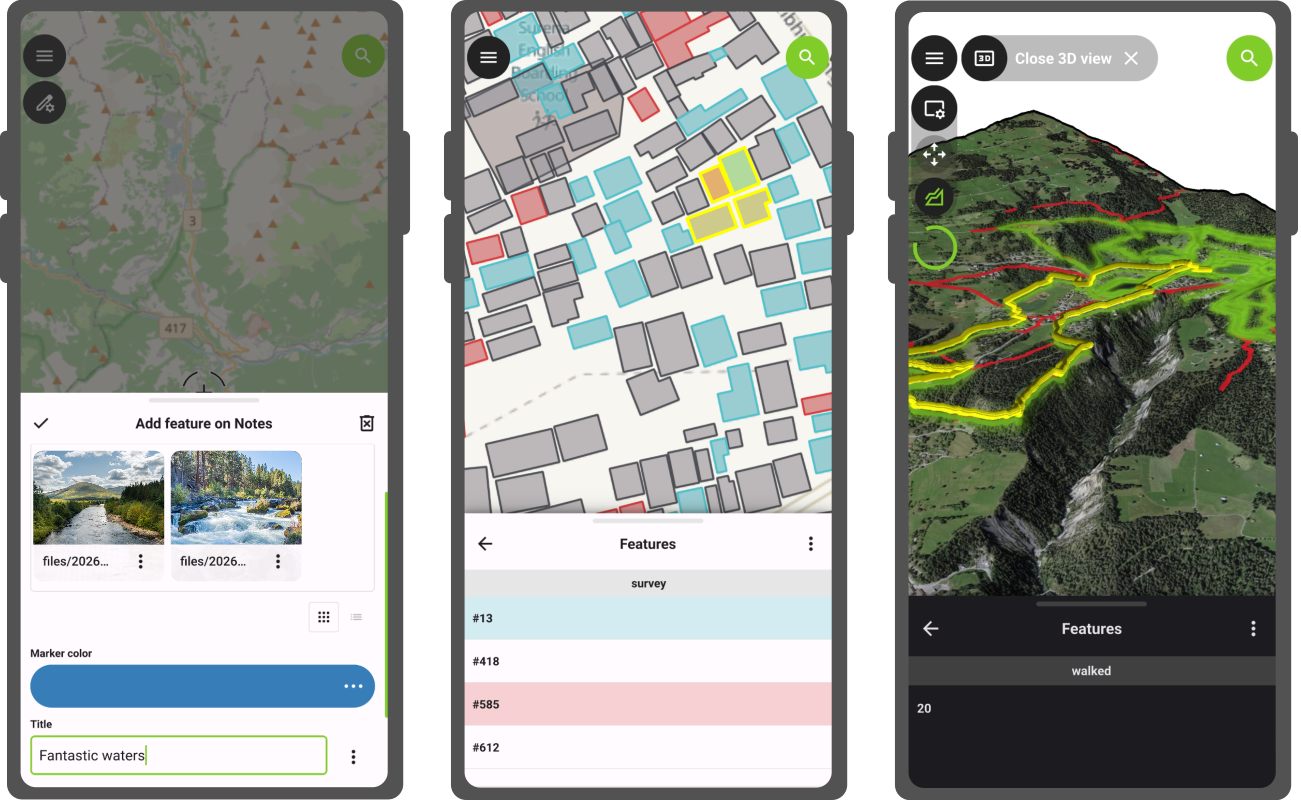
But first some education was required. I gave several workshops (see below) to learn mobile mapping with
EveryDoor
and StreetComplete
.
The latest workshops I even provided in Spanish (with some help of local friends)! Also some CoMaps
instruction,
as people get lost while hiking using Google Maps.
There is one website for these workshops, also for self-study:
alpumapa.xyz
, or in Spanish at alpumapa.xyz/es
.
5. Conferences - Attended
Below conferences and meetups I attended in 2022-2025, in chronological order.
6. Talks & Workshops - Provided
Below talks and workshops I provided in 2022-2025, latest first.
A complete list of presentations
is available.
"Mapeando con tu móvil para OpenStreetMap" - Válor - Granada - Spain - alpumapa.xyz/es
(in Spanish) - [PDF Slides]
.
"OpenStreetMap Mobile Mapping Workshop" - Maptime AMS July 2025
- alpumapa.xyz
- [PDF Slides]
.
"Natural Navigation Workshop" - Party Niene Jeroen - Unconference - July 12, 2025
- [PDF Slides]
.
"Natural Navigation (plus some evolution of navigation)" - MaptimeAMS - Summertime Meetup - June 25, 2025
- [PDF Slides]
.
"Mapas y Tapas. A personal story of starting a local mapping community in Andalusia, Spain" - MaptimeAMS - Springtime Mapping Party - April 16, 2025
- [PDF Slides]
.
"Wie MapLibre und Vektorkarten die Welt übernehmen" - FOSSGIS 2025, Múnster, Germany
- March 26, 2025 - abstract
- VIDEO
- [PDF Slides]
.
"Docker for Geo Workshop - Provided March 2025" - [PDF Slides]
.
"OpenStreetMap Workshops - Provided in Spain Feb 2025 - Alpumapa - Mapas y Tapas" - alpumapa.xyz
- [PDF Slides]
.
"Basisregistraties en OpenStreetMap mixen voor map5topo kaarten" - FOSS4G-BE-NL - Baarle - Sept 26, 2024
- [PDF Slides]
.
"Melting Dutch open data and OpenStreetMap into a single schema" - MaptimeAMS - End of Summer Meetup - Sept 19, 2024
- [PDF Slides]
.
"Travel with Locative Media" - MaptimeAMS - Summertime Meetup - July 11, 2024
- [PDF Slides]
.
"pygeoapi mid-year update 2024" - with Tom Kralidis a.o. - FOSS4GE 2024, Tartu, Estonia
- July 3, 2024 - [HTML Slides]
- [Abstract]
.
"Diving into pygeoapi" - FOSS4GE 2024, Tartu, Estonia
- July 2, 2024 - Workshop (4h): using pygeoapi to cover publishing geospatial data to the Web, and using the API from QGIS, OWSLib and a web browser - [HTML Startpage]
- [Abstract]
.
"Doing Geospatial in Python" - FOSS4GE 2024, Tartu, Estonia
- July 2, 2024 - Workshop (4h): introduction to performing common GIS/geospatial tasks using Python geospatial tools such as OWSLib, Shapely, Fiona/Rasterio, GeoPandas and common geospatial libraries like GDAL, PROJ, pycsw, as well as other tools from the geopython toolchain. - [HTML Startpage]
- [Abstract]
.
"map5topo - A New&Fresh Topographic Map of The Netherlands" - MaptimeAMS - Mapping the Future - October 12, 2023
- [PDF Slides]
.
"map5topo - een nieuwe, frisse topokaart van Nederland" - FOSS4GNL Middelburg - September 14, 2023
- [PDF Slides]
.
"OpenStreetMap: Slim de kaart editen met apps!" - Met Casper Kersten
- FOSS4GNL Middelburg - September 13, 2023
- [Workshop Website]
- [PDF Slides]
.
"GeoHealthCheck - A Quality of Service Monitor for Geospatial Web Services" - with Tom Kralidis - FOSS4G 2023
- June 30, 2023 - [HTML Slides]
- [Abstract]
.
"pygeoapi project status 2023" - with Tom Kralidis a.o. - FOSS4G 2023
- June 30, 2023 - [HTML Slides]
- [Abstract]
.
"Diving into pygeoapi" - FOSS4G 2023
- June 27, 2023 - Workshop (4h): using pygeoapi to cover publishing geospatial data to the Web, and using the API from QGIS, OWSLib and a web browser - [HTML Startpage]
- [Abstract]
.
"Doing Geospatial in Python" - FOSS4G 2023
- June 26, 2023 - Workshop (4h): introduction to performing common GIS/geospatial tasks using Python geospatial tools such as OWSLib, Shapely, Fiona/Rasterio, GeoPandas and common geospatial libraries like GDAL, PROJ, pycsw, as well as other tools from the geopython toolchain. - [HTML Startpage]
- [Abstract]
.
"Additions to pygeoapi for Geonovum Tender (with GeoCat) - April 20, 2023 - Online - [HTML Slides]
.
"map5topo - a New Topographic Map of The Netherlands" - Geomob Barcelona - November 22, 2022
- [PDF Slides]
.
"Introducing map5topo - a new Topographic Map of The Netherlands" - Information Sessions - Oktober 5+6, 2022 - Online - [PDF Slides]
.
"GeoHealthCheck - A Quality of Service Monitor for Geospatial Web Services" - FOSS4G 2022
- August 24, 2022 - [HTML Slides]
- [Abstract]
.
"Diving into pygeoapi" - FOSS4G 2022
- August 22, 2022 - Workshop (4h): using pygeoapi to cover publishing geospatial data to the Web, and using the API from QGIS, OWSLib and a web browser - [HTML Startpage]
- [Abstract]
.
"Doing Geospatial in Python" - FOSS4G 2022
- August 22, 2022 - Workshop (4h): introduction to performing common GIS/geospatial tasks using Python geospatial tools such as OWSLib, Shapely, Fiona/Rasterio, and common geospatial libraries like GDAL, PROJ, pycsw, as well as other tools from the geopython toolchain. - [HTML Startpage]
- [Abstract]
.
"GitOps and Containerisation for INSPIRE - April 21, 2022 - Online - Geonovum Operationeel INSPIRE Overleg - [PDF Slides]
.
"GitOps and Containerisation for INSPIRE - Automation in Building, Testing and Deployment of Software Applications - February 4, 2022 - Online - European Commission - INSPIRE Maintenance and Implementation Group (MIG) - 68th MIG-T Meeting
- [PDF Slides]
.
"Enforcing Automation in Building, Testing and Deployment of Software Applications - January 24, 2022 - Online - Emerging approaches for data-driven innovation in Europe
- [PDF Slides]
- [Video Recording on YouTube]
.