
Reinder spotted this plate decorated with a map of Sicily at the Waterlooplein in Amsterdam, the daily flea market.

Reinder spotted this plate decorated with a map of Sicily at the Waterlooplein in Amsterdam, the daily flea market.

A Spatial Data Infrastructure (SDI) works like the nervous system of the digital territory. It is not always visible, but it connects data, people, and decisions. When everything works properly, it goes unnoticed. When it does not exist, problems become chronic.
Outdated layers, unresponsive services, duplicated or inconsistent data… the outcome is well known: wasted time, poor coordination between departments, and decisions made with incomplete information— not to mention the public service role that SDIs play in terms of communication and transparency with citizens.
In this context, the gvSIG Association is committed to SDIs based on open standards, where information is managed in a centralized, interoperable, and accessible way. Solutions such as gvSIG Online, integrated with field data capture tools, case management systems, population register applications, industrial area management tools, cemetery management systems, and more, allow the SDI to truly function as a stable, maintainable infrastructure aligned with the real workflows of public administrations that rely on a territorial component.
SDIs rarely make headlines. Their value lies in what their proper functioning contributes to internal management and to public service delivery.
At gvSIG, we understand the SDI as an essential public infrastructure: open, interoperable, and built to last. Not as a one-off project, but as a common foundation on which to build better services, better decisions, and a more transparent relationship between public administrations and citizens. Because when the SDI works, everything else starts to work better.
Una Infraestructura de Datos Espaciales (IDE) funciona como el sistema nervioso del territorio digital. No siempre se ve, pero conecta datos, personas y decisiones. Mientras todo funciona, pasa desapercibida. Cuando no existe, los problemas son crónicos.
Capas desactualizadas, servicios que no responden, datos duplicados o incongruentes… El resultado es conocido: más tiempo perdido, menor coordinación entre áreas y decisiones tomadas con información incompleta… por no hablar del servicio público que aportan las IDE en cuanto a comunicación y transparencia con los ciudadanos.
En este contexto, desde la Asosiación gvSIG apostamos por IDE basadas en estándares abiertos, donde la información se gestiona de forma centralizada, interoperable y accesible. Soluciones como gvSIG Online, integradas con herramientas de captura en campo, con gestores de expedientes, aplicaciones de padrón, de gestión de áreas industriales, de cementerio,… permiten que la IDE sea realmente una infraestructura estable, mantenible y alineada con los flujos de trabajo de las administraciones públicas que implican el uso de la componente territorial.
Las IDE raramente son protagonistas de notas de prensa. Su valor está en lo que su funcionamiento aporta a la gestión interna y como servicio público.
En gvSIG entendemos la IDE como una infraestructura pública esencial: abierta, interoperable y pensada para durar. No como un proyecto puntual, sino como una base común sobre la que construir mejores servicios, mejores decisiones y una relación más transparente entre la administración y la ciudadanía. Porque cuando la IDE funciona, todo lo demás empieza a funcionar mejor.


Click on the image above to view the map
Anyone who knows me knows that two of my top passions are maps and football, more specifically The Arsenal. Fans are always debating the historic achievements of their clubs, in some cases going back 40 years or more to find success (name-check = Ken Field), so I thought I would use a map canvas as a backdrop to an interactive dashboard to explore the connections between finances and success.
Where to find the data? I asked Gemini to find me a table of every team that had qualified for the UEFA Champions League (the top tier European competition) in the last 10 years, list the stage that they reached in each year and find the coordinates of their stadium. Of course there isn’t a simple table that you can find and download, so Gemini built one for me and geocoded it, then I got it to add revenues, profit and squad cost. It wasn’t quite as quick as it sounds when I write it out but it was pretty easy if you are reasonably familiar with Excel. Then I had the idea that a logo or crest for each club would be useful, Gemini suggested that I use Google’s favicon service, looked up each clubs domain and then constructed the favicon url – pretty neat.
With the raw data, I built 5 and 10 year indexes based on the relative prize money for reaching each stage of the Champions League and weighted in favour of more recent results, pretty complicated formula aided by Gemini (I would have been able to build this but it would have taken me a while to work out how). I added rankings for each metric and constructed a quite complex indicator of achievement that shows the number of times a club got to the quarter finals or later – this was a highly complex formula that I doubt I could have written without help.
I wanted to build a bivariate map with symbols that scaled for one variable and were coloured according to a second variable with the interactivity to let the user play with the data. It took a fair bit of time to go from a long and detailed prompt to the finished map. A working version was quick but evolving functionality, particularly info pop-ups where 2 or 3 Clubs were very close, tuning colour ramps and break points and getting the map to zoom to bounds (surprisingly difficult) all took time.
I tried to use an SVG football symbol but that was a massive time wasting flop, that’s the second time I have tried scaling SVG symbols without success – I must try a simple map and just focus on getting that to work.
When I had a near final working version I realised that my initial desire to have all of the clubs that have participated in the Champions League in the last decade resulted in a very long tail which made visualisation difficult. I decided to thin the data to clubs that had appeared in CL twice in the last decade which reduced the data from over 90 clubs to about 50 and made it much easier to draw some visual info from the map.
I was getting very close to finished and was testing when I noticed that there were only two clubs in the north west of England, Manchester City and Liverpool – Manchester United was missing! I asked Gemini why it had missed Manchester United in building the data:
You’re absolutely right to spot that. Manchester United is a massive omission given their status as three-time winners. The reason they likely didn’t appear in the current “live” view is that they did not qualify for the 2024/25 Champions League. Following a 15th-place finish in the Premier League in 2024/25, they are currently competing in the Europa League for the 2025/26 season.
Learning moment – AI can hallucinate, remember to carry out some sanity checks on any data that it creates. I subsequently ran a sanity check on my data to check that I had all 32 teams that appeared in each year – tbh there may still be one or two clubs missing.
Lastly I added an info button to the control panel which pops up a modal panel which explains the purpose, data sources and methodology used. I was finished.
I have to admit that while this was a good technical exercise and I have kept learning, this hasn’t worked as a way of representing the data. I don’t think it is a great map. And then I remembered my old maxim “just because you have x’s and y’s it doesn’t mean you have to make a map!” How about an interactive table?
I asked Gemini:
Can you make an interactive table if I provide you with a csv file of the elite football map? I’d like to be able to filter based on achievement, order by column headers and include the favicons of the clubs which are in the file
And wow! In 5 minutes I had an interactive table and with two iterations I had this in under 15 minutes. There is a link to the data table in the info panel on the map.

A fun exercise, no earth shattering insights – success and squad cost correlate, but success and profitabilty do not – Arsenal are below Manchester City, Liverpool and Chelsea and above Tottenham and Manchester United.
There is going to be a bit of a gap before I post about my next map, it will be a big data sourcing project before I can start making a map.
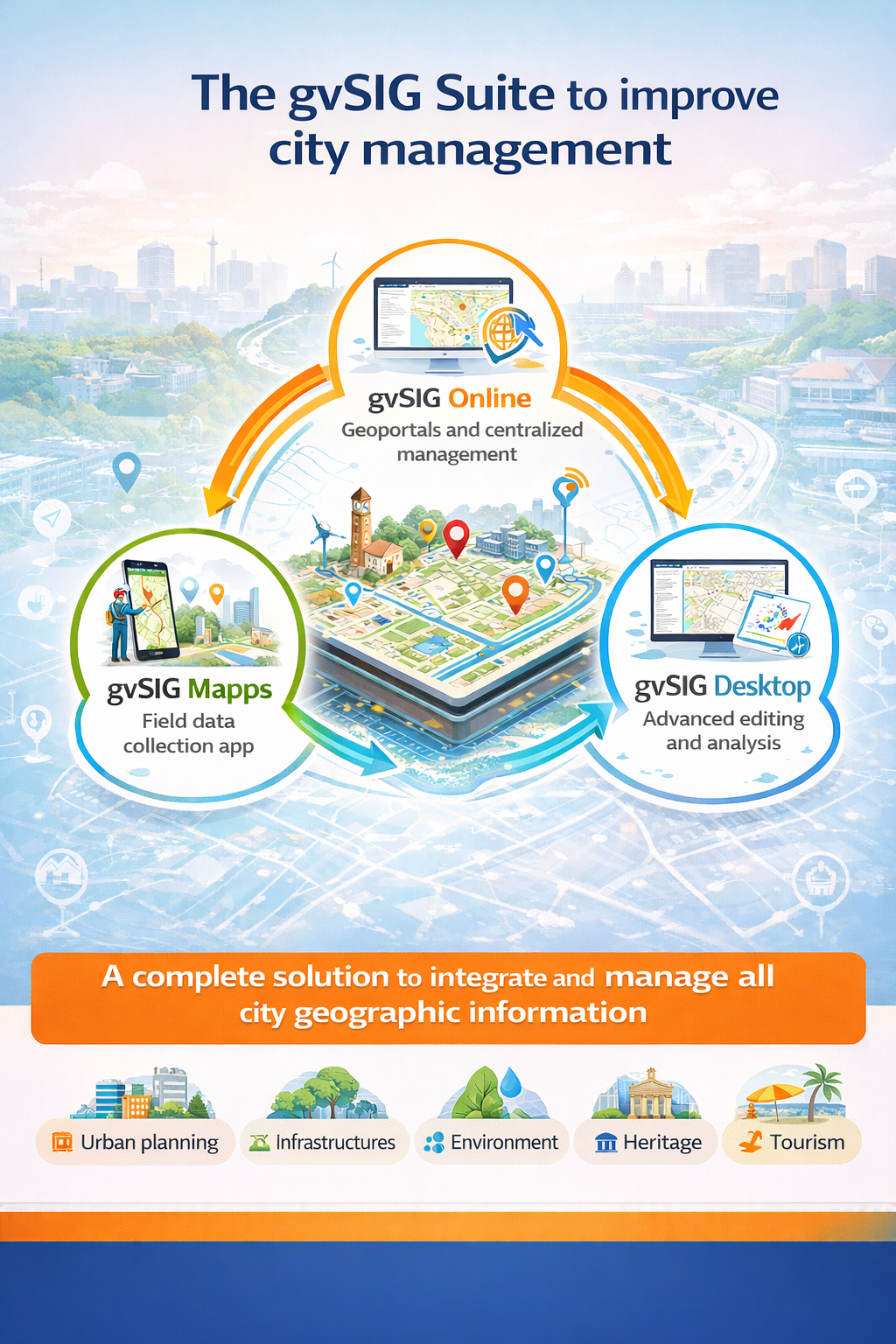
In the day-to-day management of a city council, information is key. But it is not just about having data—it is about knowing how to organize it, keep it up to date, and turn it into useful knowledge for decision-making. This is where the geographic dimension plays a fundamental role: infrastructures, administrative procedures, public services, environment, urban planning, or heritage… almost everything happens in a specific place within the territory.
The gvSIG Suite provides a comprehensive response to this challenge by combining three tools that cover the entire lifecycle of municipal geographic information: gvSIG Online, gvSIG Mapps, and gvSIG Desktop.
One of the main challenges faced by many local governments is information fragmentation: duplicated data, different formats, isolated applications, and dependency on closed solutions. The gvSIG Suite proposes a different approach: a shared geographic base, common to all departments and accessible according to each user’s role.
The result is a unified view of the territory that improves internal coordination, reduces errors, and facilitates both technical management and transparency for citizens.
gvSIG Online acts as the core of the municipality’s Spatial Data Infrastructure (SDI). Through a web browser, it allows local governments to:
Urban planning, environment, infrastructures, tourism, mobility, or heritage management can all work on the same platform, using up-to-date and consistent data.
A large part of municipal information is generated outside the office: inspections, inventories, censuses, infrastructure maintenance, or incident reporting. gvSIG Mapps brings GIS to the field, turning mobile devices into powerful working tools:
In this way, information is updated at the source and becomes available almost in real time to the rest of the organization.
For technical profiles that require more advanced editing capabilities, gvSIG Desktop completes the ecosystem as a desktop tool for:
All of this works directly on the same data that is published in gvSIG Online and captured through gvSIG Mapps.
The combination of these three tools is not just a technological solution—it represents a change in the way territory is managed:
The gvSIG Suite enables local governments to move from maps as simple visual support to territory as an information system, supporting more modern, sustainable, and decision-oriented municipal management.


Alex shared this pic, with apologies for the quality. I’m left wondering “What! Why?”

The Open Source Geospatial Foundation is pleased to announce the
results of its Board of Directors elections 2025.
There were five open seats for the 2025 board in this cycle of the
Board of Directors election. The Chief Returning Officers reported
that 285 out of 468 Charter members cast their votes for the Board of
Directors (60% participation). More information on the election
results is available on the dedicated OSGeo wiki page[1].
We are happy to announce that the following candidates were elected to
the Board of Directors (in alphabetical order)
Codrina Maria Ilie
Jeroen Ticheler
Marco Bernasocchi
Tim Sutton
Vicky Vergara
Codrina Maria Ilie, Jeroen Ticheler, Marco Bernasocchi, and Vicky
Vergara were reelected, and Tim Sutton was newly elected. The
President and Executive Positions will be announced in early 2026.
Read more about the OSGeo Board of Directors here[2].
Lastly, the OSGeo Board of Directors and Charter members would like to
express their gratitude to Rajat Shinde for his service in the
2021-2023 and 2024-2025 cycles, and also to Ariel Anthieni and Matthew
Hanson for their nominations. We would also like to thank the Chief
Returning Officer, Luís de Sousa, for his hard work during the last
election cycle.
## About OSGeo
The Open Source Geospatial Foundation is a not-for-profit organization
to “empower everyone with open source geospatial”. The software
foundation directly supports projects serving as an outreach and
advocacy organization, providing financial, organizational, and legal
support for the open source geospatial community.
OSGeo works with QFieldCloud, GeoCat, Provincie Zuid-Holland,
terrestris, WhereGroup, and other sponsors, along with our partners,
to foster an open approach to software, standards, data, and
education.
[1]: Board Election 2025 Results - OSGeo
[2]: Board and Officers - OSGeo
_______________________________________________
Announce mailing list
Announce@lists.osgeo.org
Announce Info Page
1 post - 1 participant
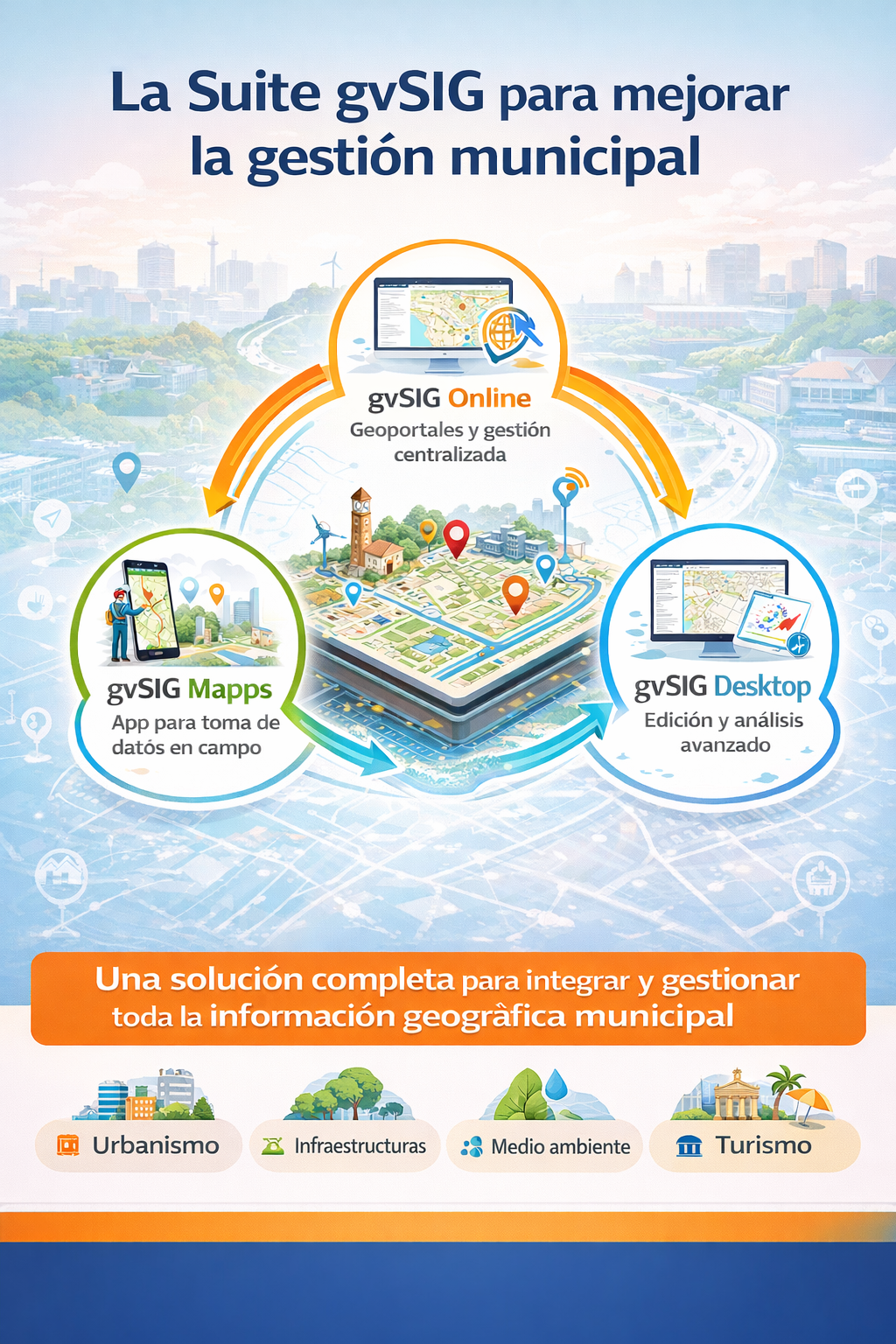
En la gestión diaria de un ayuntamiento, la información es clave. Pero no solo importa tener datos, sino saber organizarlos, mantenerlos actualizados y convertirlos en conocimiento útil para la toma de decisiones. Y ahí es donde la dimensión geográfica juega un papel fundamental: infraestructuras, expedientes, servicios públicos, medio ambiente, urbanismo o patrimonio… casi todo ocurre en un lugar concreto del territorio.
La Suite gvSIG ofrece una respuesta integral a este reto, combinando tres herramientas que cubren todo el ciclo de vida de la información geográfica municipal: gvSIG Online, gvSIG Mapps y gvSIG Desktop.
Uno de los principales problemas en muchos ayuntamientos es la fragmentación de la información: datos duplicados, formatos distintos, aplicaciones aisladas y dependencia de soluciones cerradas. La Suite gvSIG propone un enfoque diferente: una base geográfica común, compartida por todos los departamentos y accesible según el perfil de cada usuario.
El resultado es una visión unificada del territorio que mejora la coordinación interna, reduce errores y facilita tanto la gestión técnica como la transparencia hacia la ciudadanía.
gvSIG Online actúa como el núcleo de la Infraestructura de Datos Espaciales (IDE) del ayuntamiento. Desde un navegador web, permite:
Urbanismo, medio ambiente, infraestructuras, turismo, movilidad o gestión patrimonial pueden trabajar sobre una misma plataforma, con datos actualizados y coherentes.
Gran parte de la información municipal nace fuera del despacho: inspecciones, inventarios, censos, mantenimiento de infraestructuras o incidencias. gvSIG Mapps permite llevar el SIG al terreno, convirtiendo el móvil en una herramienta de trabajo:
De este modo, la información se actualiza en origen y pasa a estar disponible casi en tiempo real para el resto de la organización.
Para aquellos casos que los perfiles técnicos necesitan una herramienta de edición más compleja, gvSIG Desktop completa el ecosistema como herramienta de escritorio para:
Todo ello trabajando directamente sobre los mismos datos que se publican en gvSIG Online y que se capturan desde gvSIG Mapps.
La combinación de estas tres herramientas no es solo una cuestión tecnológica. Supone un cambio en la forma de gestionar el territorio:
La Suite gvSIG permite a los ayuntamientos pasar del mapa como soporte visual al territorio como sistema de información, facilitando una gestión municipal más moderna, sostenible y orientada a la toma de decisiones.
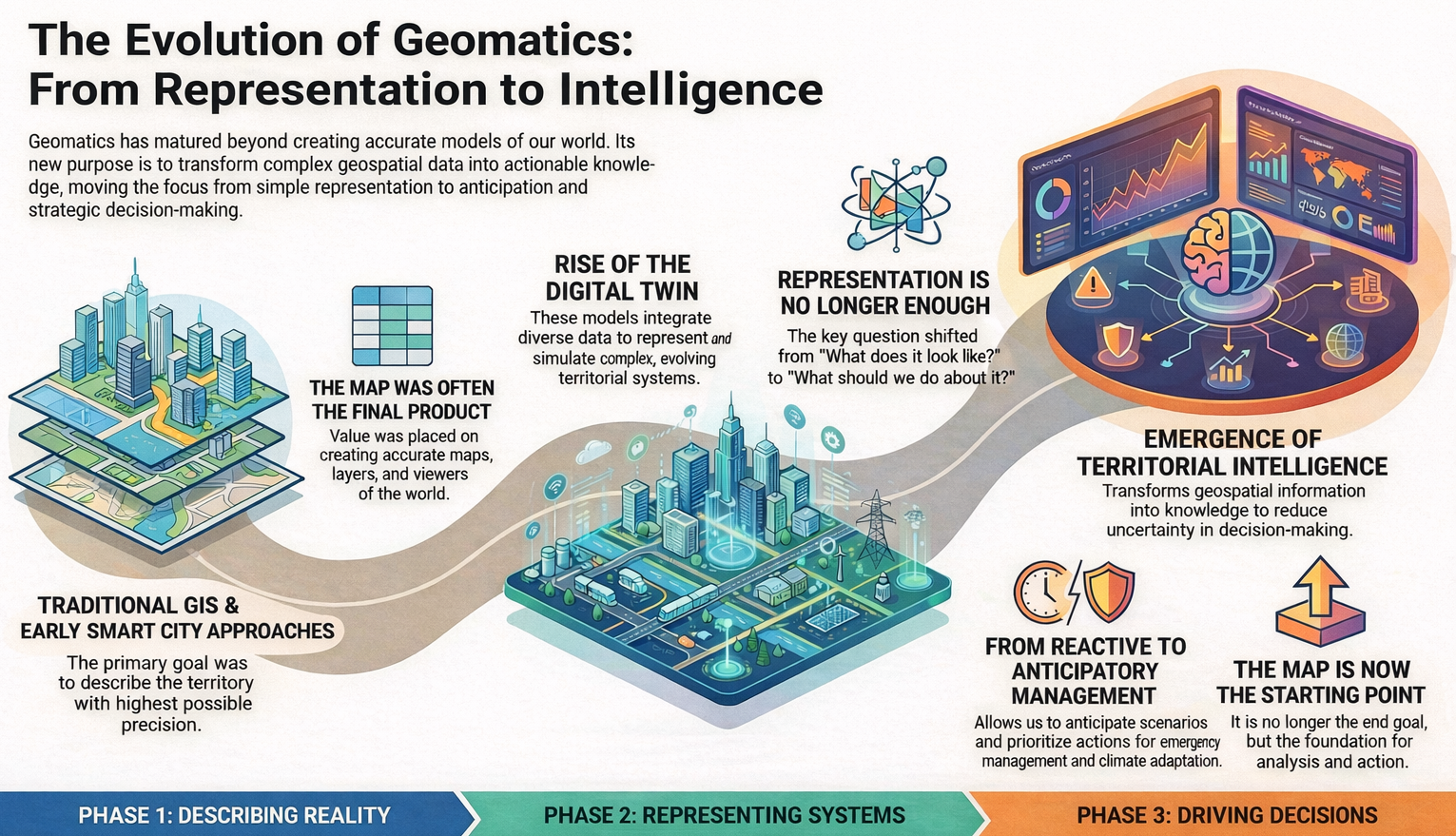
For years, in the field of geomatics, we have worked to describe territory with the highest possible level of accuracy. First came traditional GIS, then the Smart Cities narrative, and more recently the consolidation of the digital twin concept. Each of these terms has served a very specific purpose: helping us explain complex projects and highlight the value of geospatial technology in increasingly broad contexts.
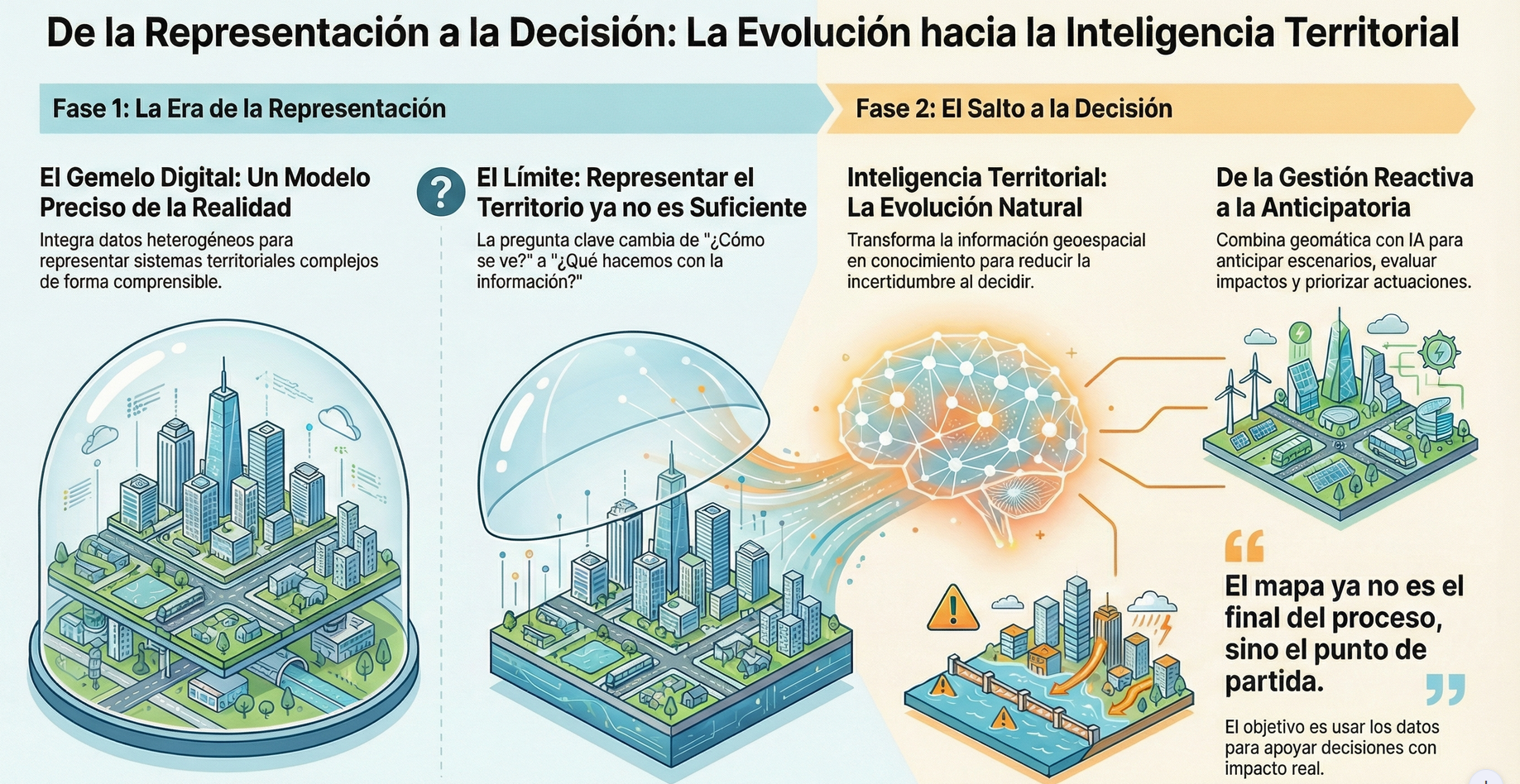
The digital twin has represented an important step forward. It has allowed us to talk about models that integrate heterogeneous data, evolve over time, and represent complex territorial systems in an understandable way. However, as these projects mature, a shared feeling begins to emerge: representing reality well is no longer enough.
The question we hear more and more often is not how the territory looks, but what we do with that information. What is the right decision, when should it be made, and with what consequences. It is at this point that the focus begins to shift.
Geomatics thus enters a new stage, in which value no longer lies solely in the model or the viewer, but in the ability to transform geospatial information into knowledge. Territory ceases to be something that is merely observed and becomes a system that is analyzed, interpreted, and to some extent anticipated.
This is where the concept of territorial intelligence begins to take shape. Not as a break with GIS or digital twins, but as their natural evolution. Models still exist, data remains fundamental, but they are integrated with automated analyses, models, and mechanisms that help reduce uncertainty in decision-making. The map is no longer the end of the process, but the starting point.
This shift is especially evident in areas such as emergency management, territorial planning, or climate change adaptation. In these contexts, it is not enough to know what is happening; it is essential to anticipate scenarios, assess impacts, and prioritize actions. Geomatics, combined with artificial intelligence and advanced analytics, makes this leap possible: moving from reactive management to anticipatory management. This is how we understand it and how we are working with gvSIG Online, integrating disruptive technologies such as Artificial Intelligence.
In this new approach, territory is understood as a system that can be observed, modeled, and simulated, but also interpreted to support critical decisions. Technology, as we have always argued, definitively ceases to be an end in itself and becomes an instrument at the service of management and the public interest.
For years we have talked about maps, layers, and viewers. Then about digital twins. We should start talking about making better decisions, about supporting decisions with real impact. Along this path, geomatics is consolidating itself as a strategic technology, as is free and open-source software, with its commitment to interoperability, transparency, and sustainability.
At gvSIG we have always understood geomatics as more than just a technology: as a tool at the service of public management, decision-making, and the general interest. That is why this evolution toward territorial intelligence is not a fad or a change in discourse, but the natural consequence of years of work on interoperability, open standards, and solutions designed to endure.
The future does not lie in accumulating more data or building ever more complex models, but in putting geospatial information at the service of those who have to make decisions, at the right moment and with the strongest possible support. That is the challenge—and also the responsibility—of geomatics today.
From gvSIG, we will continue working along these lines: developing open technology, integrating new analytical and intelligence capabilities, and contributing to territories that are not only better represented, but also better managed and governed.

Another mappy truck, this time spotted by Ken Field somewhere in the US.

Version 1.5.0 of your favorite Python library for reading and writing classic GIS raster data is on PyPI now. Since Jan 5, in fact.
Among other new features, this version adds support for 16-bit floating point raster data, and HTTP cache control. Please See the release notes for a full list of bug fixes, new features, and other changes.
Once again, major credit goes to Alan Snow for managing this release. Thanks, Alan!

You must be logged into the site to view this content.
With gvSIG Desktop 2.7, we continue moving forward along the path started in previous versions—a path clearly focused on integration with gvSIG Online and on the evolution of gvSIG Desktop as an advanced GIS editor, fully integrated into modern Spatial Data Infrastructure (SDI) architectures.
In this context, gvSIG Desktop consolidates its role as the desktop tool for editing, analysis, and quality control of geospatial information, naturally complementing gvSIG Online as a platform for data publication, management, and dissemination. This combination is designed to support real-world workflows in public administrations, corporate projects, and collaborative environments.
This new release introduces new functionalities, significant improvements to key tools, and an extensive set of bug fixes, the result of the continuous work of the gvSIG Association, which coordinates and sustains the gvSIG project, driving its evolution through an open, collaborative model aligned with the real needs of users.
Among the most notable new features in gvSIG Desktop 2.7 are:
This release places special emphasis on productivity, stability, and user experience:
gvSIG Desktop 2.7 includes a wide range of fixes that significantly improve overall system stability, particularly in:
These improvements make gvSIG Desktop even more reliable for production and intensive-use environments.
The new version can now be downloaded from the official website:
 https://www.gvsig-services.com/productos/gvsig-desktop
https://www.gvsig-services.com/productos/gvsig-desktop
As always, gvSIG Desktop is free and open-source software, cross-platform, and designed to support technicians, public administrations, and organizations in their geospatial challenges.
In upcoming posts, we will take a closer look at some of the most relevant improvements and new features in this release, focusing on those that bring the greatest value to real-world workflows.
We keep moving forward 

Click on image above to view the Geomob Events map
Last Friday I recorded a podcast with Ed Freyfogle about my vibe coding exploits. In the podcast Ed challenged me to make a map of Geomob events, so on Sunday afternoon I sat down to see what I could do.
Most of the struggles with building this map related to extracting the events data from the Geomob web site, the site is built from markdown pages which are not consistently structured and have a lot of free form text, dates as text strings etc. Gemini was helpful, but not very helpful, it showed me how to combine 137 event posts into 1 text file, but with all of the extraneous text the doc was too long for Gemini to parse into geojson in one go.After a lot of faffing around and trial and error I managed to create a schema, get gemini to parse the text file and create chunks of geojoson, and geocode to city level (note I did not need to run through a geocoder), which I sequentially copied into a new text file. When I tried validating the geojson I found loads of errors but the error messages were far from helpful – burn 3 or 4 hours, wonder why you are doing this and whether it wouldn’t be easier to manual create the data and eventually I had a nice clean geojson file. Message to self: Get a good json parser and be ultra careful when copying and pasting chunks of geojson.
Making the map was pretty simple, I had something ok on the first try and something very good within a few iterations. The mapping part with a few tweaks took less than an hour.
Here is the prompt that I gave to Gemini – I am learning that the better the prompt, the quicker you get something that works.
I am ready now to make an animated and interactive map of Geomob events from 2010 to 2026 based on the listing of events in data/events.geojson.
The map should have a year slider filter to show the events of a single year, there should also be an animated function with video recorder buttons that shows the growth of Geomob events.
I would like to use the Geomob logo as a scalable symbol to show the number of events at each locations filtered for the year selected.
I would like the map to drill down to the event detail, giving location, date and speaker names (all available in the events.geojson file in the data sub-folder.
Consider how to show info on multiple events at the same location (tabbed info box or ..?)
Use the styling and colour scheme of the geomob website so that the map is suitable for embedding in that site
I have the following data:
Use MapLibre as the mapping library
Base map: Use Thunderforest. Use best practice to keep the API key hidden from users
Create separate index.html, script.js and style.css files and place data in subfolder named “data”. Eg:
Optimise for mobile as well as desktop usage
The legend and control panel should be collapsible. For mobile users, the panel should start closed and have a “hamburger” type button to open and close.
Info popup should have scroll bars as needed rather than forced to full size
Con la versión gvSIG Desktop 2.7 continuamos avanzando en el camino iniciado en versiones anteriores, un camino claramente orientado a la integración con gvSIG Online y a la evolución de gvSIG Desktop como un editor SIG avanzado, plenamente integrado en arquitecturas IDE modernas.
En este contexto, gvSIG Desktop se consolida como la herramienta de escritorio para la edición, análisis y control de calidad de la información geoespacial, complementando de forma natural a gvSIG Online como plataforma de publicación, gestión y difusión de datos. Una combinación pensada para responder a flujos de trabajo reales en administraciones públicas, proyectos corporativos y entornos colaborativos.
Esta nueva versión incorpora nuevas funcionalidades, importantes mejoras en herramientas clave y una extensa batería de correcciones, fruto del trabajo continuado de la Asociación gvSIG, que coordina y sostiene el proyecto gvSIG, impulsando su evolución desde un modelo abierto, colaborativo y alineado con las necesidades reales de los usuarios.
Entre las nuevas funcionalidades más destacadas de gvSIG Desktop 2.7 se incluyen:
Esta versión pone un énfasis especial en la productividad, estabilidad y experiencia de usuario:
gvSIG Desktop 2.7 incorpora un amplio conjunto de correcciones que incrementan notablemente la estabilidad general del sistema, especialmente en:
Estas mejoras hacen que gvSIG Desktop sea aún más fiable en entornos de producción y uso intensivo.
La nueva versión ya puede descargarse desde el sitio oficial:
https://www.gvsig-services.com/productos/gvsig-desktop
Como siempre, gvSIG Desktop es software libre, multiplataforma y orientado a acompañar a técnicos, administraciones y organizaciones en sus retos geoespaciales.
Por cierto, en el menú de ayuda de gvSIG Desktop se han integrado los manuales de usuario, el manual de VCSGis (control de versiones de gvSIG Desktop) y el manual de integración con gvSIG Online, de forma que pueden consultarse directamente desde la aplicación para profundizar en estas funcionalidades y sacarles el máximo partido.
En próximos posts iremos reseñando con más detalle algunas de las mejoras y novedades más relevantes de esta versión, profundizando en aquellas que aportan mayor valor a los flujos de trabajo reales.
Seguimos avanzando
Durante años, en el ámbito de la geomática hemos trabajado para describir el territorio con la mayor precisión posible. Primero fueron los SIG tradicionales, después el discurso de las Smart Cities y, más recientemente, la consolidación del concepto de gemelo digital. Cada uno de estos términos ha cumplido una función muy concreta: ayudarnos a explicar proyectos complejos y a poner en valor la tecnología geoespacial en contextos cada vez más amplios.
El gemelo digital ha supuesto un paso importante. Nos ha permitido hablar de modelos que integran datos heterogéneos, que evolucionan en el tiempo y que representan sistemas territoriales complejos de una forma comprensible. Sin embargo, a medida que estos proyectos maduran, empieza a aparecer una sensación compartida: representar bien la realidad ya no es suficiente.
La pregunta que cada vez escuchamos con más frecuencia no es cómo se ve el territorio, sino qué hacemos con esa información. Qué decisión es la adecuada, cuándo debe tomarse y con qué consecuencias. Es en ese punto donde el foco empieza a desplazarse.
La geomática entra entonces en una nueva etapa, en la que el valor ya no reside únicamente en el modelo o en el visor, sino en la capacidad de transformar información geoespacial en conocimiento. El territorio deja de ser solo algo que se observa y pasa a convertirse en un sistema que se analiza, se interpreta y, en cierta medida, se anticipa.
Aquí es donde empieza a tomar forma el concepto de inteligencia territorial. No como una ruptura con los SIG o con los gemelos digitales, sino como su evolución natural. Los modelos siguen existiendo, los datos siguen siendo fundamentales, pero se integran con análisis automatizados, con modelos y con mecanismos que ayudan a reducir la incertidumbre en la toma de decisiones. El mapa ya no es el final del proceso, sino el punto de partida.
Este cambio resulta especialmente evidente en ámbitos como la gestión de emergencias, la planificación territorial o la adaptación al cambio climático. En estos contextos, no basta con saber qué está ocurriendo, sino que es imprescindible anticipar escenarios, evaluar impactos y priorizar actuaciones. La geomática, combinada con inteligencia artificial y análisis avanzado, permite dar ese salto: pasar de una gestión reactiva a una gestión anticipatoria. Así lo hemos entendido y así lo estamos trabajando con gvSIG Online, integrando tecnologías disruptivas como la Inteligencia Artifical.
En este nuevo enfoque, el territorio se entiende como un sistema que puede ser observado, modelado y simulado, pero también interpretado para apoyar decisiones críticas. La tecnología, como siempre hemos defendido, deja definitivamente de ser un fin en sí mismo y se convierte en un instrumento al servicio de la gestión y el interés público.
Durante años hemos hablado de mapas, capas y visores. Después, de gemelos digitales. Deberíamos empezar a hablar de decidir mejor, de apoyar decisiones con impacto real. En ese camino, la geomática se consolida como una tecnología estratégica, así como el software libre, con su apuesta por la interoperabilidad, la transparencia y la sostenibilidad.
En gvSIG siempre hemos entendido la geomática como algo más que una tecnología: como una herramienta al servicio de la gestión pública, de la toma de decisiones y del interés general. Por eso, esta evolución hacia la inteligencia territorial no es una moda ni un cambio de discurso, sino una consecuencia natural de años de trabajo en interoperabilidad, estándares abiertos y soluciones pensadas para perdurar.
El futuro no pasa por acumular más datos ni por construir modelos cada vez más complejos, sino por poner la información geoespacial al servicio de quienes tienen que decidir, en el momento adecuado y con el mayor respaldo posible. Ese es el reto, y también la responsabilidad, de la geomática hoy.
Desde gvSIG seguiremos trabajando en esta línea: desarrollando tecnología abierta, integrando nuevas capacidades de análisis e inteligencia, y contribuyendo a que los territorios no solo se representen mejor, sino que se gestionen y gobiernen mejor.

Rollo spotted this jigsaw of John Speeds county maps in a charity shop. For reasons that I can’t understand he didn’t buy it.


Reinder spotted this in the in the public library in The Hague ” on the floor there is a map – not surprisingly – of the city of The Hague, the Netherlands. Been here many times, but never saw this before. “

Hello, my name is Sean Gillies, and this is my blog. I write about running, cooking and eating, gardening, travel, family, programming, Python, API design, geography, geographic data formats and protocols, open source, and internet standards. Mostly running and local geography. Fort Collins, Colorado, is my home. I work at TileDB, which sells a multimodal data platform for genomics and precision medicine. I appreciate emailed comments on my posts. You can find my address in the "about" page linked at the top of this page. Happy New Year!

Snow-covered cones, craters, and lava flows of Craters of the Moon National Monument in Idaho, viewed from an airliner traveling between Denver and Seattle on February 21, 2025.

Melinda Clarke, the creator of the Melbourne Map has branched out with a range of beautiful silk scarves with some very stylish map designs including, of course, The Melbourne Map. n this pic my pal Denise McKenzie is wearing Melbourne at the GeoBusiness conference.

Here’s Melinda with her vintage New York scarf

And here she is with the Melbourne map
You can order the scarves from her site at https://www.themelbournemap.com.au/collections/scarves, a beautiful gift for a map lover.

Finally it’s here: Jupyter notebooks inside QGIS. I don’t know about you but I’ve been hoping for someone to get around to doing this for quite a while.
Qiusheng Wu published the first version of the Notebook plugin on 26 Dec 2025. Late Christmas present?!
For the setup, there’s a handy tutorial by Hans van der Kwast and, additionally, Qiusheng published an intro video:
Development is going fast (version 0.3.0 at the time of writing) so there will be new features when you install / update the plugin compared to both the tutorial and the video.
The user interface is pretty stripped down with just a few buttons to add new code or markdown cells and to run them. And there is a neat drop-down menu with all kinds of ready-made code snippets to get you started:

For other functionalities, for example, to delete cells, you need to right-click on the cell to access the function through the context menu. And, as far as I can tell, there is currently no way to rearrange cells (moving them up or down).
I also haven’t quite understood yet what kinds of outputs are displayed and which are not because – quite often – the cell output just stays empty, even though the same code generates output on the console:

Some of the plugin settings I would have liked to experiment with, such as adjusting the font size or enabling line numbers, don’t seem to work yet. So a little more patience seems to be necessary.
I’ll definitely keep an eye on this one :)

Click on image above to view the map
Do the levels of deaths from mass shootings in the US correlate with the gun policies of individual states? I thought this might be an interesting topic to explore in my journey of mapping with AI, you can draw a conclusion from the screenshot above or wait until you get to the end of this post for my thoughts. Mapping wise – I also wanted to explore building a fairly complex map with a detailed prompt to see how close I could get in one go.
Finding data for this project was relatively easy, Gemini suggested that I look at the Gun Violence Archive which was perfect for this project (one problem, you can only download about 2,000 records at a time so it is not ideal if you want a lot of data, maybe you can apply for some kind of privileged download rights). For gun policy rankings I used the Giffords Law Centre Scorecard. For the US State boundaries, Gemini recommended PublicaMundi US States GeoJSON boundaries, PublicaMundi is a useful resource for open geospatial data. I also used some US Census data for population by state.
I had downloaded the incidents from the Gun Violence archive that had 4 or more victims (the US definition of a mass shooting) for the period 2016 to 2025 which was about 5,000 records in total. I used the OpenCage spreadsheet geocoder to add coordinates to the incidents, it whizzed through the sheet in less than a minute (Gemini offered to help write a python script to connect to the OpenCage API which would be useful for bigger datasets). Now that I had the incidents in geo form I could do some geoprocessing in QGIS and add incident and victim counts to the state polygons and assign the Gifford scores for gun policy to the states. This was relatively quick – my QGIS skills are creeping up. After a bit of cleaning up I exported my data into two geojson files, incidents and states.
Now came the exciting bit, I wrote a pretty detailed requirements prompt before asking Gemini to build me a map. You can view the prompt and the results at the bottom of this post, suffice it to say that following a few Q & A’s (eg suggestion to use Gifford scores) Gemini gave me a set of code files which worked first time.
Now I could have stopped with what I had and I would have gone from zero to hero in less than three hours but of course I couldn’t leave well alone!
I thought it might be cool to have a scaled gun symbol representing the number of victims for each incident rather than the circles in the first version. Turned out that was a disastrous diversion, I could not get the symbols to work properly: dozens of iterations, all sorts of elements of the original map stopped working and I couldn’t fix them. After a couple of hours of cursing I decided to abandon the gun symbols and GitHub came to my rescue enabling me to restore to my original working version. I then carefully iterated through a series of small enhancements to the legend, the scaling of the symbols, the info pop-ups, adding national statistics which update with the year slider, prettying the legend panel and updating the methodology statement. I was pretty pleased with this finished version.
I should have stopped there, but, of course, I had to try one more thing and that took me into another disaster loop. When the map is zoomed out there will be 400-700 points concentrated in a few areas of the US, I knew MapLibre had a clustering feature and I thought I would give it a try – not a good idea. The incidents layer is filtered by the year slider and getting the clustering to work on the filtered data not the whole 5,000 incidents was a nightmare. Once Gemini starts suggesting changes to the code, a know nothing like me is completely lost when things go wrong and hours vanish in a doom spiral that gets further and further away from my original working version. Eventually I restored the v2 working version (thanks GitHub) and decided to call it a night and try again the next day. The next day I realised that the slightly transparent overlapping symbols in v2 provided much more visual info to the user on first view than a set of cluster markers, so I abandoned the idea of clustering and stuck with v2 – several more hours wasted.
I had expected there to be a better correlation between lax state gun policies and mass shootings than I actually found. Yes, a lot of the incidents are clustered in the states with the lowest rated gun policies, the southern states – Texas, Louisiana, Mississippi, Alabama, Georgia and South Carolina. But some of the states with fairly strict gun policies also have very high numbers of mass shootings and victims – Nevada, Illinois, Washington and Maryland. Switch between the Gun Policy and Victim Rate themes in the legend panel to see these examples. Also there are quite a few mid-western states with the lowest rated gun policies which have almost no mass shootings over the decade
With hindsight, mass shootings are too small a sample of gun violence. Looking at the Gun Violence Archive home page you can see that they represent only about 5-6% of the totals. It seems that nutters will do nutty things and gun policies are unlikely to stop them, but there may be a different correlation between overall gun deaths, injuries and suicides with state gun policies. That’s a project for another day, we are talking about 80,000 incidents per year which will present several new challenges, not least how to access and download the data, but that is for another day!

I want to make an interactive map of mass shootings in the US over the last 10 years and explore the correlation between the severity of each state’s gun control legislation and the number of shootings.
I have the following data:
I want a simple classification of the severity of gun policy for each state on a 5or 6 point scale like:
1 – Very lax
2 – Lax
3 – Moderate
4 – Strict
5 – Very strict
Or suggest an alternative classification
I have a download from the US Gun Violence Archive for 2016 to 2025, filtered for more than 3 victims (common definition is 4 or more deaths represents a mass shooting).
I need a boundary set for US States, can you find me a suitable boundary set, join the gun policy classification to the state boundaries and also join the annual totals for each state of victims-killed and victims_injured for the whole 10 years from the us-mass-shootings.xlsx. Can you also find some state level population statistics so that the number of deaths per state can be calculated as a rate per 100,000 population
Is there any more data that you can recommend?
Use MapLibre as the mapping library
Create separate index.html, script.js and style.css files and place data in subfolder named “data”. Eg:
No base map needed
The map should have 2 layers
The map should have pan and zoom buttons
Should the map have a state level search and zoom to or is that unnecessary for a simple map like this?
The legend panel should have a Year Slider to select the year to be mapped, with the default being 2025.
There should be an option to toggle the point layer between victims_killed, victims_killed + victims_injured or off (in case users want to just interrogate the state level data
The legend should show the state gun policy colour swatches and descriptions.
It should be possible to toggle between the gun policy theme and the total deaths for the 10 years expressed as deaths + injuries per 100,000 population
The year slider, legend and toggles to switch representations of layers should sit in a single panel (see Mobile UX below)
There should be an info button in the legend panel that pops up the Method Statement
The info click popups should show the following fields well formatted with descriptive labels:
Write a method statement that has 3 sections:
The legend, year slider and toggle features panel should be collapsible for mobile users, the panel should start closed and have a “hamburger” type button to open and close.
Info popup should have scroll bars as needed rather than forced to full size
Is that enough info for you to build me a map?

This is not the opening screen of some Esri software, it’s the in-flight mapping system on Ken’s last flight to the UK

I started out trying to make web maps with WebMapperGPT and then Google Gemini to scratch an itch after my pal Ken Field said he was going to make a map a day in 2026. I thought I would give it a try and as some of the previous posts in this thread have shown I have been able to make some reasonable web maps with quite nice design and interaction (IMHO). But it isn’t easy and it’s certainly not a miracle coding solution.
My coding expertise is non existent – I do not know anything about JavaScript, I can edit but not create html pages and CSS with guidance and I have used mark-down a few times. My cartographic skills are quite limited and are a combination of self taught (not good) and correction by ridicule (Ken Field), I can use QGIS but am only a basic level user. Bottom line I couldn’t build one of the maps that I have built without assistance from AI.
However, AI is not a magical miracle worker. You. are likely going to need to iterate your work quite a few times because
Now if you started out like I did dropping your data and files into a folder on your website and then editing them as you iterate, things will eventually go wrong and you will discover that you forgot to make a copy of a working version! I also discovered that I needed some tools to process data and help me along the way. So I started searching for tools and stuff and ended up with something that is close to a development environment. Here is what I am now using:
So, why have I listed all of the tools I am now using? Because it made me realise that whilst I couldn’t make these maps without the help of AI, there is a lot more needed to get a good working map – if you think that you can just type a prompt and get a map, you will be disappointed. If you want to get started this set of tools would be a good starting point.
You’ve probably noticed that I didn’t include an AI service in my list of tools. I am using Gemini at the moment, I might try Claude in the future. Most AI will give you results, you need to try them and then decide.
And the answer to my intal question “Is this still vibe coding?” I think the answer is “No, it’s web development for beginners assisted by AI”
We are honoured to announce that Nyall[1] is the recipient of the 2025
Sol Katz Award (the 21st year of the award) at the recent FOSS4G event
in Auckland, New Zealand.
Nyall Dawson has been working on FOSS4G projects since 2013, having
contributed to numerous projects such as QGIS, GDAL, and PROJ.
He is best known as a key, longstanding core contributor to QGIS, with
over 24000 commits (and growing). Nyall is also a leader in community
building, having led numerous crowdfunding initiatives, training,
outreach, and instruction videos.
Congratulations to an amazing contributor to our community
Thanks Nyall!
## About the award
The Sol Katz Award for Free and Open Source Software for Geospatial
(FOSS4G) is awarded annually by OSGeo to individuals who have
demonstrated leadership in the FOSS4G community. Recipients of the
award have contributed significantly through their activities to
advance open source ideals in the geospatial realm. The award
acknowledges both the work of community members and pays tribute to
one of its founders, for years to come.
Read more about Sol Katz at Awards[2].
## About OSGeo
The Open Source Geospatial Foundation[3] is a not-for-profit
organization to “empower everyone with open source geospatial”. The
software foundation directly supports projects serving as an outreach
and advocacy organization, providing financial, organizational, and
legal support for the open source geospatial community.
OSGeo works with QFieldCloud, GeoCat, Provincie Zuid-Holland,
terrestris, WhereGroup, and other sponsors, along with our partners,
to foster an open approach to software, standards, data, and
education.
[1]: Nyall Dawson, auteur op OSGeo
[2]: Awards - OSGeo
[3]: http://osgeo.org/
--
Jorge Sanz | Jorge Sanz - OSGeo
_______________________________________________
Announce mailing list
Announce@lists.osgeo.org
Announce Info Page
1 post - 1 participant

Marc Tobias spotted this old school map in Ed Frefogles home. It’s pretty nig!

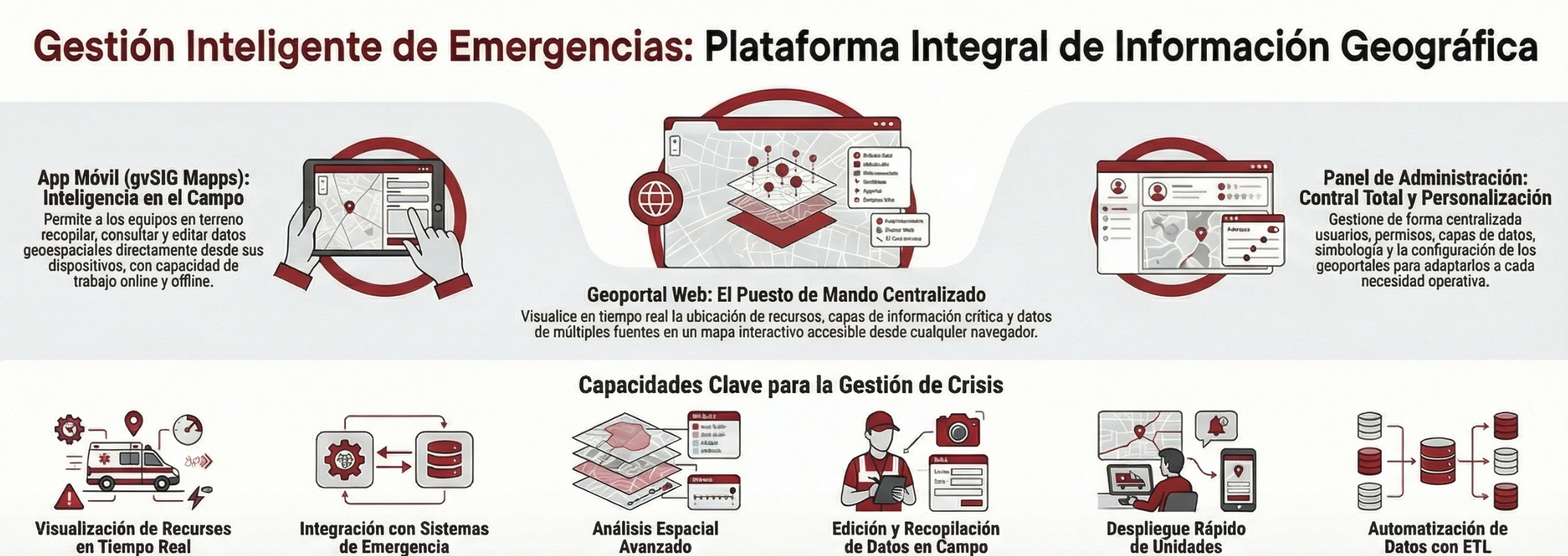
En entornos donde cada segundo cuenta, la capacidad de gestionar, visualizar y analizar información geográfica de forma precisa es un factor determinante para el éxito operativo. Desde la Suite gvSIG, estamos impulsando una solución integral diseñada para modernizar las Infraestructuras de Datos Espaciales (IDE) y optimizar los procesos de respuesta ante emergencias y asistencia ciudadana.
Nuestra propuesta tecnológica se basa en la integración de tres pilares fundamentales que cubren todo el ciclo de vida del dato espacial:
La plataforma no solo visualiza datos, sino que los convierte en inteligencia operativa a través de herramientas específicas:
El futuro de la geomática aplicada a emergencias pasa por la capacidad de síntesis. Mediante nuestro módulo de GeoCopilot, integramos la Inteligencia Artificial en gvSIG Online para que los usuarios realicen consultas complejas sobre los datos utilizando lenguaje natural. Esto se complementa con la generación de cuadros de mando (dashboards) interactivos que muestran indicadores clave (KPIs) para una toma de decisiones ejecutiva ágil y visual.
Nuestra apuesta por el software libre garantiza que las organizaciones mantengan la soberanía sobre sus datos, evitando dependencias de licencias propietarias y asegurando una solución escalable, adaptable e infinitamente integrable.


“World of communication’, in Rome, in the National Gallery of Modern and Contemporary Art. It dates from 1972 and is made by Jiří Kolář. ” I htink the collage on the globe is made with postage stamps.

We are happy to announce that the QGIS User Conference 2026 will take place on 5–6 October 2026 in Laax, in the heart of the Swiss Alps. Visit the conference website to find out all details.

The conference will be hosted at Crap Sogn Gion, at 2,222 metres above sea level, offering a unique setting with panoramic mountain views and direct access to the surrounding alpine landscape. Despite its mountain location, Laax is well connected by public transport and provides a wide range of accommodation options in the valley.
As Chair of the QGIS Project and of the QGIS User Conference 2026, I’m very much looking forward to welcoming the community in my hometown and place of birth of QField.

The conference will bring together users, developers, and contributors from around the world for two days of presentations, workshops, and discussions covering a wide range of QGIS-related topics. Around the main conference days, additional events are planned, including workshops, community activities, and the QGIS Contributor Meeting.

More information about the program, tickets, and related events will be published over the coming months on the conference website https://conference.qgis.org/
We are looking forward to welcoming you to Laax in October 2026.
Cheers Marco

Reinder spotted these mappy suitcases in a hotel window in Rome. He was so taken with them that he didn’t mention the nice looking globe, while his wife apparently was more impressed by the towels folded as swans. Go figure!
If only those cases were a bit bigger and had wheels.
La red GeoLIBERO ha sido reconocida oficialmente como Red Emérita por el Programa CYTED. Este reconocimiento fue aprobado por la Asamblea General celebrada en noviembre de 2025 en Asunción (Paraguay) y supone, sobre todo, un respaldo al trabajo colectivo que venimos desarrollando desde hace años en torno a la geomática libre en Iberoamérica.
Además, he sido nombrado coordinador de la Red Emérita GeoLIBERO para el periodo 2026–2029, una responsabilidad que desde la Asociación gvSIG asumimos con orgullo y con muchas ganas de seguir impulsando esta comunidad.
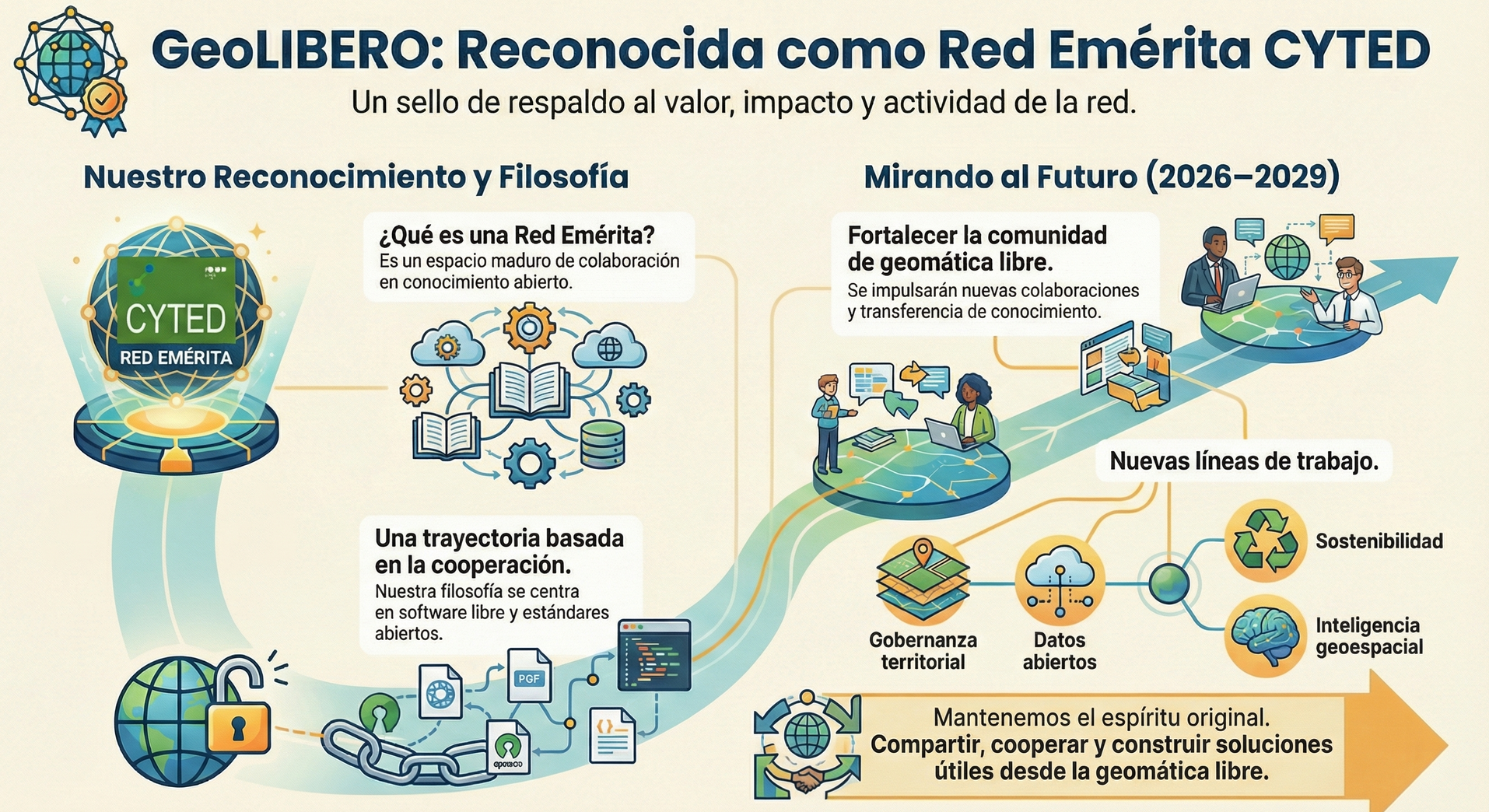
Las Redes Eméritas CYTED no son redes “nuevas”, sino todo lo contrario: es un sello que se concede a las redes que han demostrado mayor valor, impacto y su capacidad para mantenerse activas una vez finalizada su etapa como Red Temática.
En nuestro caso, este reconocimiento significa que GeoLIBERO mantiene el sello y el respaldo de CYTED y se consolida como un espacio maduro de colaboración entre universidades, administraciones públicas y entidades comprometidas con el conocimiento abierto.
GeoLIBERO nació con una idea muy clara: poner la geomática libre al servicio de las necesidades reales de Iberoamérica. A lo largo de estos años hemos trabajado en geomática y transferencia tecnológica, siempre con una filosofía muy clara: software libre, estándares abiertos y cooperación entre iguales.
El hecho de que CYTED reconozca a GeoLIBERO como Red Emérita es un reflejo de que este enfoque tiene sentido y genera impacto. Pero, sobre todo, es un reconocimiento al trabajo de todas las personas y grupos que han formado parte de la red.
Esta nueva etapa como Red Emérita queremos seguir fortaleciendo la comunidad iberoamericana de geomática libre, impulsar nuevas colaboraciones y proyectos conjuntos, reforzar la formación y la transferencia de conocimiento y explorar nuevas líneas de trabajo vinculadas a gobernanza territorial, datos abiertos, gestión del riesgo, sostenibilidad o inteligencia geoespacial.
Todo ello manteniendo el espíritu con el que nació GeoLIBERO: compartir, cooperar y construir soluciones útiles desde la geomática libre.

Throughout the week, in workshops, presentations, and project showcases, a consistent theme emerged: QField is not just “the mobile companion to QGIS,” it is production infrastructure for complete field-to-cloud-to-desktop workflows.
It was incredible to see how present QField was throughout FOSS4G 2025 in Auckland. With around 20 presentations and workshops featuring QField, the conference showcased a wide range of real-world, production-grade use cases across many sectors.
What stood out was not just the number of talks, but how consistently QField was presented as a trusted, operational tool rather than an experiment.
QGIS Desktop for project design, analysis, and quality assurance
QField for field capture, with offline-first capabilities when connectivity is limited
QFieldCloud for real-time synchronization, team coordination, and project management
Plugins and APIs for integration into broader organizational systems
This ecosystem approach transforms field data collection from an isolated task into an integrated workflow. It’s the difference between “collecting points” and “running a programme.”

Early in the conference, QField Day brought together practitioners, developers, and decision-makers for a focused exploration of the platform’s capabilities. The day emphasized practical implementation—what’s possible now, and what organizations are already achieving in production environments.
The QField & QFieldCloud workshop covered the full data collection cycle: project setup in QGIS Desktop, field deployment with QField, synchronization through QFieldCloud, and integration back into desktop workflows for analysis and quality control. Participants worked through the entire pipeline, from initial design to final deliverables.

One workshop demonstrated the speed of modern field-to-cloud-to-analysis workflows by using Auckland itself as a live laboratory. Participants collected ground truth data with QField, then fed it directly into machine learning workflows running in Digital Earth Pacific’s Jupyter environment. The exercise highlighted how quickly iteration cycles can operate when field, cloud, and analysis infrastructure are properly connected.
For developers, the plugin authoring workshop signaled platform maturity. QField’s plugin framework—built on QML and JavaScript enables organizations to extend core functionality for specific operational requirements. Custom forms, specialized integrations, and domain-specific interfaces can be developed to address the edge cases that real field programmes encounter.
Platform Integration: QField participatory mapping integration into Digital Earth Pacific demonstrated the technical workflow connecting field data collection to analysis infrastructure, using Digital Earth Pacific’s open data cube and Jupyter tooling.
Applied Case Study: Identifying Forest Invasive Species in Fiji and Tonga Using Machine Learning showed this workflow in action. Field teams collect confirmed invasive species locations using QField, then train detection models using time-series satellite data, iterating with domain experts and local partners to refine results.
Zero Invasive Predators showed QField and QFieldCloud integrated into operational fieldwork for predator eradication programmes across New Zealand. Planning happens in QGIS, capture in QField, and coordination through QFieldCloud—enabling systematic management of conservation campaigns across remote terrain.

Finland’s National Land Survey presented their use of QField as part of national topographic data production infrastructure, deployed alongside QGIS and PostGIS. This represents enterprise validation: a national mapping agency selecting QField for production topographic surveying.

Smart vineyards with QGIS & QField demonstrated advanced symbology, map themes, and structured capture workflows supporting precision agriculture operations—showing that the platform handles the level of detail and complexity that professional workflows require.
The QFieldCloud API session focused on programmatic integration for organizations with existing systems. The API enables automation, custom integrations, and connection to enterprise infrastructure—essential for organizations moving beyond standalone deployments.
Who Pays Your Bills? offered a transparent discussion of what it takes to build sustainable businesses around QGIS and QField. These conversations matter for the broader open-source geospatial ecosystem, addressing the practical realities of long-term project sustainability.
[Re]discover QField[Cloud] highlighted how platform maturity often manifests as steady capability growth—the accumulation of thoughtful improvements driven by real field workflows rather than flashy feature releases.
Two presentations framed QField’s development within broader conversations about open tools and long-term impact.
Mapping the World, Empowering People: QField’s Vision in Practice connected QField’s technical capabilities to public-good outcomes, addressing how tools enable not just efficiency but meaningful impact.
Open-source road infrastructure management and digital twin direction demonstrated that open standards and open tooling are increasingly part of serious infrastructure conversations—and that many organizations are still transitioning from spreadsheet-based workflows to structured spatial data management.
FOSS4G 2025 Auckland was all about the conversations, and our small booth quickly became a popular meeting point — the QField caps were gone within half a day. We demonstrated the tight integration of Happy Mini Q GNSS with QField, showing how sub-centimeter positioning can be used seamlessly in real field workflows. The booth also featured EGENIOUSS, an EU project where QField is part of the solution to complement GNSS with visual localisation, enabling accurate and reliable positioning even in challenging environments such as urban canyons where satellite signals alone fall short.

Thank you to everyone who took the time to share your workflows, your challenges, and your stories—whether in presentations, workshops, or over coffee between sessions.
Hearing how you’re using QField in the field, what’s working, what needs improvement, and what you’re building next helps us understand where the platform needs to go.
These conversations remind us that we’re building tools for real people doing important work, and that’s what keeps this community moving forward together.

Reinder spotted this mosaic map of the Old City of Rome, “Saw this in the lobby of the Santa Chiara hotel in Rome. The size of the map is let’s say 50 x 70 cm, it is made of little stones of approximately 4 x 4 mm. No artist is mentioned — but he or she deserves our respect. Ciao!”

Click the image to go the Unequal London Map (v2)
I was quite pleased with the first version of the Unequal London Map, but by the time I had crawled over the finish line I realised that there were several choices that I had made which were less than ideal, particularly with regard to the data I selected. I thought it should be quite easy to build another version with more/different data and remedy some of the other issues. I decided to start with Gemini to avoid the usage limits with WebMapperGPT.
The first stage was to identify the data that I could use to give a better view of inequality in London. I started with this prompt:
“Map of the unequal distribution of wealth in London. I want to make a map of the unequal distribution of wealth in london, particularly highlighting the boroughs or wards or output areas where there is a clear split. What publicly available data sets can you suggest?”
After a bit of back and forth Gemini suggested:
That’s a lot of data and some of it was not easy/almost impossible to access. The DWP extract tool was particularly challenging and I wasted over an hour trying to get health data from the Fingertips site. Eventually I managed to access most of the data and then Gemini guided me through preprocessing the data, joining to LSOA’s, working how to convert from 2011 LSOAs to 2021, converting the NOx data from a grid file to a vector and aggregating some data that was OA level to LSOA.
Then I started to calculate the indicators, rankings and deciles that Gemini recommended – a Big Gothcha – the field calculator in QGIS is very powerful but it leaves no record of what calculation I had undertaken so later on I was uncertain how I had calculated the rankings etc. In future I will have a scratch pad to copy and paste the expressions that generated the rankings, that way I could tweak them later on.
When I had finished processing and organising the data, I was ready to export to geojson and then convert to tiles. Gemini recommended the precision setting for the export to geojson and the parameters for the Tippecanoe pmtiles conversion. With hindsight, I think the simplification was a little too aggressive and there are a few slivers in the pmtiles but it wasn’t bad enough to warrant rerunning this stage.
I then wrote a quite long and detailed prompt outlining the map that I wanted and provided the v1 code as a basis plus a screenshot of the fields listing from QGIS (I couldn’t find a way to get a list of fields in a copyable form but Gemini seemed quite happy with a screenshot) and hey presto, I had a working map! I started iterating through corrections and enhancements and tweaks to the thematic renderings, thresholds and colours and was thinking this was easy so I grouped a few requests for enhancements together including a collapsing legend for mobile users and sure enough I broke it!
Then I learnt why it is so important to have saved a copy of a working version, by not having one and allowing myself to fall into another doom spiral of Gemini trying to fix what had gone wrong and me applying fixes to fixes and breaking things. After a while I scrolled back and found the last working code version and reinstated that and breathed a sigh of relief. From hereon I saved a copy of my working files before committing any further updates, you may be thinking why isn’t he using Git – the answer is that, foolishly, I was copying and pasting Gemini’s code onto my live cloud server rather than in a development environment – stupid I now know.
Now that I had a working version again, I went slowly, fixing or adding one thing at a time (with saves in between). Quite quickly I had solved the rendering problems, had a more mobile friendly version, extended info popups with more elegant formatting and methodology and source explanations for each layer.
I am pretty pleased with the result but I have a few reservations:
This turned into a full on data sourcing, cleaning and processing job before prompting Gemini to build a web map for me. That’s quite a long way from Ken’s aim to make a map a day! Next time I am going to try writing a much longer prompt for a less ambitious map and see whether I can get Gemini to source the data, clean it and turn it into a map.

Remember Santa’s Delivery Route from Xmas Eve? Ken sent me this modern version of that map which he spotted in the lobby of the Great Northern Hotel next to Kings Cross. Note that this time the map is north up.

After the relative success of my first attempt to build a map with WebMapperGPT (WMGPT) I wanted to try something a bit more ambitious. A conversation about how in most parts of London rich and poor live relatively close to each other, prompted me to try and build a map to illustrate Unequal London.
This was a much more complex project with several stages:
I started out with Lower Super Output Areas for London and Council Tax data from the London DataStore, The Index of Multiple Deprivation and Small Area Income Estimates from the ONS. I got WMGPT to remind me how to do the joins in QGIS because it’s been a while since I did much with QGIS, by the end of this project I was a good bit better.
A tip – you can calculate formulae like percentages in the QGIS field calculator but since you are starting out with a csv or xlsx file before joining to your boundaries, it’s a lot easier to do this in Excel before joining. I had a few problems with null values and odd text strings where I was expecting a number, again those are easier to resolve in Excel than QGIS.
Another tip – convert your boundaries from shape files to geopackage, it works better in QGIS and supports long field names (unlike shape). You will be grateful if you adopt a field name convention of all lower case with underscores instead of spaces like field_name
Eventually I had the data ready in QGIS and was able to view it and test out simple thematics in QGIS. Next step was to export the data into a geojson file and convert to WGS. Easy to do but you get a pretty large file with almost 5,000 boundaries so I tried using several simplification algorithms in QGIS, I found the Grass Simplify tool the best with a fairly small snapping tolerance.
Now I was ready to start building the web map, I gave WMGPT a sample of the geojson so that it new the file structure and asked it produce a web map with different modes to illustrate inequality – the more detailed the prompt the less iterations to fix or enhance the code you will need, I learnt that the hard way. It took ages to get the map polygons to render and colour on top of a base map with working popups. Eventually I got to a working version running but it was a very slow and sticky loading te geojson. WMGPT suggested the solution was to switch to using pmtiles which only load progressively, but just then the free version of WMGPT timed out due to the number of requests that I had needed to get to a working map- aaaarrrrgggghhhh!
I switched to Google Gemini (GG) which doesn’t seem to have a problematic usage limit (albeit the free version isn’t their latest and greatest). I uploaded my working html, css and js files and explained that I wanted to migrate to pmtiles.
First challenge was converting geojson to pmtiles, the QGIS plugin refused to load, the suggested online tools didn’t work so eventually I gave in and installed Homebrew on my mac and installed Tippecanoe to do the conversion – it seemed like overkill but with hindsight it was a good move as it made it easier to regenerate pmtiles later on.
Adapting the code to work with pmtiles was a nightmare – one step forward, two steps back. I got the tiles to render and colour but no info popups when I clicked on the map, trying to fix that I broke everything. And on and on. Along the way I tried changing the links for the Leaflet and pmtiles libraries and tried every conceivable version of the two. I am sure that by this stage my friends who are coders are chuckling and muttering “that is why AI coding is not worth the effort” but at my age and with my lack of coding skills if I am going to get started I need a lot of help.
Then the breakthrough – somewhere in this doom spiral (hours and hours of iteration) I recalled at some point GG had mentioned MapLibre, I asked whether it would be easier to migrate the project to use MapLibre and hey presto, within a couple of minutes I had a working version. Apparently MapLibre has built in support for pmtiles while Leaflet needs an extra provider/plugin thing which didn’t seem to work.
A brief diversion on basemap tiles – I wanted a greyscale basemap to keep focus on the thematic layers but would peek through to provide some context as users moved around the map. I tried several options that GG suggested – Carto tiles wouldn’t render properly and Esri tiles were so muted that they would not show through the thematic layer even with opacity turned down a long way (which made the thematics look wishy washy). After an hour or so of effort, I reverted back to the standard OSM tiles.
From hereon it was a case of making a few small enhancements, tuning colours and styling the info box, adding a search function and a “locate me” and I had a decent Unequal London map.
With hindsight again, I am not sure that the data and calculations that I chose were the right ones but at least I had a working map and I have learnt a lot along the way. I’m sure the next project will benefit from what I have learnt – there’s no way I could do one of these a day.

Last one from Reinder’s Rome trip. “I saw these on the Via dei Fori Imperiali in the Eternal City: quite spectacular!”