
Just in case you didn’t know where it comes from the distillers of Longitude 77 put a map on the label. Via Elizabeth

Just in case you didn’t know where it comes from the distillers of Longitude 77 put a map on the label. Via Elizabeth

It appears that I haven’t posted anything here for a year! There are some mitigating circumstances though.
TL;DR; I didn’t die and I have a new job.
Coincidently, about a year ago I started to struggle with my mental health. Initially I didn’t worry too much as the onset of winter and the clocks going back always adversely affects my mood, and living in Scotland makes this worse as it gets lighter later and dark earlier than when we lived further south. Normally, I would expect for my mood to pick up in the new year when the days lengthen and its safe to go outside again. But this year it didn’t, I don’t know why, maybe working at a university wasn’t as much fun as I had hoped it to a. Certainly it turns out that just being called a research software engineer didn’t make as much of a difference to my quality of life as I had hoped it would. I struggled on until Easter time (which was clearly a mistake with hindsight), when it became clear to everyone and even me that I needed to take some time off. So anyone who was hoping to meet up with me at GISRUK I’m sorry but I really couldn’t face travelling or meeting people. I spent much of April in bed sleeping while I waited for a bigger dose of anti-depressants to kick in (this can be between 6 and 10 weeks, on top of the fortnight to wean off the previous ones).
I also started taking Manjaro to help with my weight and diabetes along with a tailored exercise program, so by the end of May I had lost 10 kilos and was feeling pretty good about life in general. Then …
As many of you will have heard I suffered a significant health issue in early June when my colon decided that it had had enough and decided to start bleeding unexpectedly. I went out for dinner one evening with some friends from university and the next thing I really knew was I was in a critical care ward with the staff explaining to me again and again that I was unwell. Between the loss of blood and morphine I was handling this information very poorly. This confusion wasn’t helped by the fact that I knew the Royal Victoria Infirmary (RVI) in Newcastle very well from my student days as we used to use its historic corridors as a (dry) short cut to and from the university most days. This hospital was clearly much newer and shinier than the one I remembered. It turns out the old one was knocked down and replaced by student flats some years ago.
I had to come to terms with a) having nearly died (though I don’t remember), b) no longer having a colon and an Ileostomy and having a scar from waist to sternum (held together with massive staples) and c) having a stoma bag attached to me (most of the time).
Anyway, after 10 days or so I was considered well enough to move to a normal ward, though I promptly let my blood pressure collapse and was moved back to ICU for some magnesium, but eventually I was well enough to transfer back to Scotland. I can’t say I recommend travelling up the M74 in an ambulance but it was good to be back near to home, especially for Lesley.
After another week on a high dependency ward in East Kilbride (since I had transferred from ICU as there were no “normal” beds available for me to take in Newcastle) I had to go into an HDU bed (I know). I was easting normally, finally, and could walk from one end of the ward to another (lying in bed for a fortnight really kills your muscle tone) and I was allowed to go home.
Early the next week I went back for a stoma clinic checkup and the nurses took one look at me and decided that maybe I should visit the ambulatory emergency unit (despite, or because, needing a wheelchair to get there). They promptly readmitted me as my blood pressure was down below 80, which explained why I wasn’t feeling too chipper. I spent a few more days in hospital being given IV magnesium and antibiotics to sort out my blood pressure and inflammatory markers. Things could have been worse, the guy in the next bed had a gall stone the size of a tennis ball taken out of his intestines as it had bored its way out off his gall bladder. The surgeons were very excited and had taken pictures of it to show him.
Recovering, took much longer than I expected though all the medical staff kept saying how tough an operation was. This meant that I wasn’t well enough to travel to Mostar for FOSS4GEU which again was a shame (especially since I had been organised enough to actually book travel and hotels in advance). So again sorry if you were hoping to catch up with me there.
My contract at Glasgow ended at the start of October, which was about when my doctors were becoming happy for me to go back to work. I had half heartedly filled out some applications for new university jobs and dumped my CV on various job sites. Though to be honest I was really looking forward to being able to say in January that clearly I was unemployable and should consider retirement. Sadly (or happily) I got a call from a recruiter who seemed desperate to hire me (but couldn’t really say why). He was offering a quite silly amount of money with the only catch being the need to incorporate. So, I agreed to an interview and it turned out to be with a system integrator who was working for His Majesty’s Land Registry (HMLR) who maintain the English and Welsh cadastral register. Quite why they were so keen to hire me was still unclear but I said yes to a six month contract. When I started at the HMLR it became clear why they wanted me, they are trying to update part of the register (the only vectorized part) from a proprietary format that was developed by Envitia (who I had worked for back in 2011-15) and were trying to convert to a PostGIS DB using GeoTools to build a Java tool.

Meet Hefni Azzahra – our new QGIS documentation writer, joining us from Indonesia!
Hefni holds a Bachelor’s degree in Geodetic Engineering and brings a strong background in geospatial science and mapping to the QGIS project. She’s passionate about GIS and has a curious mind that loves exploring new tools and ideas — a great match for the QGIS documentation team!
In her new role, Hefni will help improve and expand QGIS documentation, from clarifying existing tools to making new features easier to understand for users of all levels.
Outside of work, she enjoys swimming (her favorite!), going to the gym, painting, and discovering cozy cafés.
We’re excited to have her on board. Welcome to the team, Hefni!

L’Imaginere shared this map of streets on the pavement in Ath, somewhere to the east of Lille.
You can find it on an OSM project called “A Map of Maps” which says “On this map you can find all maps OpenStreetMap knows – typically a big map on an information board showing the area, city or region, e.g. a tourist map on the back of a billboard, a map of a nature reserve, a map of cycling networks in the region, …). If a map is missing, you can easily map this map on OpenStreetMap.” What a great project!

Você sabia que o GeoServer pode armazenar toda a sua configuração (workspaces, stores, layers, styles) em um banco de dados PostgreSQL, em vez de gravar arquivos XML no diretório data_dir?
Isso é possível com dois módulos da comunidade: JDBCConfig e JDBCStore. Apesar de frequentemente usados juntos, eles têm funções diferentes e complementares.
 1. O que é o JDBCConfig
1. O que é o JDBCConfig
O JDBCConfig é um módulo que permite ao GeoServer salvar toda a configuração do catálogo(metadados) dentro de um banco relacional, como o PostgreSQL.
Por padrão, o GeoServer armazena sua configuração em diversos arquivos XML dentro do diretório data_dir — um para cada workspace, store, camada e estilo. Com o módulo JDBCConfig, essas informações deixam de ser gravadas nesses arquivos e passam a ser persistidas diretamente em tabelas no banco de dados, substituindo por completo o backend de configuração baseado em arquivos.
1.1 O que ele armazena
1.2 Vantagens
1.3 Quando usar
 2. O que é o JDBCStore
2. O que é o JDBCStore
O JDBCStore é outro módulo comunitário que complementa o JDBCConfig. Ele permite armazenar os arquivos reais do data_dir (como estilos .sld, imagens, legendas e uploads) dentro do banco de dados, em vez de no sistema de arquivos.
Diferente do JDBCConfig, que salva metadados e estrutura do catálogo, o JDBCStore salva conteúdo binário (arquivos, blobs).
2.1 O que ele armazena
2.2 Vantagens
2.3 Quando usar
 3. Relação e diferenças entre JDBCConfig e JDBCStore
3. Relação e diferenças entre JDBCConfig e JDBCStore
Embora os dois módulos sejam frequentemente mencionados juntos, eles têm propósitos distintos dentro do GeoServer.
O JDBCConfig é responsável por armazenar as configurações do catálogo, ou seja, toda a estrutura de metadados que descreve o funcionamento do GeoServer, os workspaces, as conexões com bancos de dados, as camadas e os estilos associados. Ele substitui o modelo tradicional baseado em arquivos XML, gravando essas informações diretamente em tabelas no banco de dados.
Já o JDBCStore atua em outro nível: ele armazena o conteúdo físico dos arquivos que normalmente ficam no data_dir. Isso inclui estilos (.sld, .css), imagens, legendas e qualquer outro arquivo binário usado pelo GeoServer. Em vez de deixar esses recursos no sistema de arquivos, o JDBCStore os grava como blobs dentro do banco.
Os dois módulos podem funcionar independentemente. Você pode usar apenas o JDBCConfig, mantendo os arquivos (como SLDs) ainda no disco ou apenas o JDBCStore, guardando os arquivos no banco, mas deixando o catálogo em XML.
No entanto, o uso conjunto dos dois traz o máximo de benefícios: a configuração e os recursos do GeoServer passam a ser totalmente centralizados e sincronizados no banco de dados, eliminando a necessidade de um diretório compartilhado via NFS.
Resumindo:
 4. Como instalar o JDBCConfig e o JDBCStore no GeoServer 2.28.0
4. Como instalar o JDBCConfig e o JDBCStore no GeoServer 2.28.0
4.1 Baixar os módulos
Acesse a página de Community Modules da sua versão: https://geoserver.org/release/2.28.x/
Baixe os arquivos:
geoserver-2.28.x-jdbcconfig-plugin.zip
geoserver-2.28.x-jdbcstore-plugin.zip
Extraia os .jar e copie para:
GEOSERVER_HOME/WEB-INF/lib/
4.2 Criar o banco no PostgreSQL
Crie um novo banco vazio, por exemplo:
CREATE DATABASE geoserver_catalog; CREATE USER geoserver_user WITH PASSWORD 'senha_segura'; GRANT ALL PRIVILEGES ON DATABASE geoserver_catalog TO geoserver_user;
4.3 Configurar o JDBCConfig
Após o primeiro restart do GeoServer com o módulo instalado, será criada a pasta:
data_dir/jdbcconfig/
Dentro dela há um arquivo de exemplo jdbcconfig.properties.postgres. Edite-o e configure conforme abaixo:
enabled=true initdb=true import=true ... username=geoserver_user password=senha_segura jdbcUrl=jdbc:postgresql://localhost:5432/geoserver_catalog
Salve o arquivo como jdbcconfig.properties, reinicie o GeoServer e observe no log, se tudo estiver certo, ele criará as tabelas automaticamente e importará sua configuração XML atual para o banco.
4.4 Configurar o JDBCStore
Após instalar o módulo jdbcstore, um diretório semelhante será criado:
data_dir/jdbcstore/
Edite o arquivo jdbcstore.properties (também há um .postgres de exemplo):
enabled=true initdb=true ... username=geoserver_user password=senha_segura jdbcUrl=jdbc:postgresql://localhost:5432/geoserver_catalog
Reinicie o GeoServer novamente.
 5. Conclusão
5. Conclusão
O uso do JDBCConfig e do JDBCStore traz uma série de benefícios, especialmente em ambientes de alta disponibilidade ou clusterizados.
Eles permitem que toda a configuração e os recursos do GeoServer sejam armazenados de forma transacional, centralizada e sincronizada dentro de um banco de dados relacional.
Mas mesmo em ambientes sem cluster, esses módulos podem ser vantajosos para quem busca:
E você leitor, conhecia esses módulos do GeoServer? O que achou? Deixe seu comentário, vou gostar de saber sua opinião.


Desde siempre, en Geomatico hemos hecho agilismo. En nuestra búsqueda por ofrecer el mejor servicio a las empresas con las que colaboramos, creemos que una de las mejores maneras de hacerlo es aplicando metodologías ágiles.
El agilismo llegó a Geomatico antes que el propio Geomatico. Ya en 2009 asistíamos a Open Spaces sobre agilismo, cuando todavía no estaba tan bien visto utilizarlo.
Durante años fuimos profundizando en la metodología y aprendiendo de la experiencia de aplicarla en la vida real. Han sido muchas las herramientas que hemos probado y muchas las discusiones sobre qué son realmente los puntos de historia, qué significa una historia de 10 puntos frente a una de 3, y cómo conciliar todo eso con nuestra realidad en la gestión económica de los proyectos.
Hace un par de años decidimos certificarnos en Scrum Manager, una certificación que permite desarrollar el currículo profesional en Scrum a través de cursos y exámenes de acreditación. Así, en 2023 obtuvimos la certificación como Scrum Master. El objetivo no era tanto conseguir el título (aunque siempre se agradece), sino pulir ciertos aspectos de la metodología con los que no nos sentíamos del todo cómodos.
En 2025 realizamos el curso de Product Owner, y obtuvimos también esa certificación. Esto nos permitió mejorar nuestros procesos de definición de producto con el cliente y optimizar algunos aspectos de la gestión de proyectos.
En definitiva, el agilismo es parte esencial de nuestra forma de trabajar y de entender los proyectos. Más que una metodología, es una actitud que nos impulsa a mejorar de manera constante, a aprender de la experiencia y a adaptarnos a los cambios con flexibilidad. En Geomatico hemos construido una cultura de equipo basada en la confianza, la comunicación y el aprendizaje compartido. Esa forma de trabajar es la que nos permite ofrecer soluciones más eficientes, humanas y sostenibles, y la que seguiremos cultivando para crecer junto a nuestros clientes y colaboradores.
 Los valores ágiles con los que nos sentimos complemente identificados y no solo en el desarrollo de software (Tomado de @jrgsanta)
Los valores ágiles con los que nos sentimos complemente identificados y no solo en el desarrollo de software (Tomado de @jrgsanta)

David Sherren sent us this pic which he took in The Old Customs House, Gunwharf Quays, Portsmouth. He said “Anyone who is familiar with Portsmouth Harbour will know that it is not actually joined to Gosport by a land bridge, as appears to be the case on this decorative chart!” I have to confess I am not familiar with Portsmouth Harbour but now I want to go there to view the map and check its lack of veracity.


Walter Schwartz sent us this pic from his trip to Nepal, he said “We visited a modest 24-student school for ages 3 to 11 in a small village outside the mountain town of Lumle, Nepal. The principal’s office features a desk with a world map desk pad and a display globe. The value of maps in education is ubiquitous.”
We agree with Walter hence the title of this Map in the World.


GeoServer 3 is a major upgrade led by a consortium of Camptocamp, GeoSolutions, and GeoCat and backed by a successful crowdfunding activity.
This is a major investment in the future of GeoServer and we are pleased to provide a project update. The GeoServer 3 code sprint completed last week, and we have quite a list of accomplishments to share.

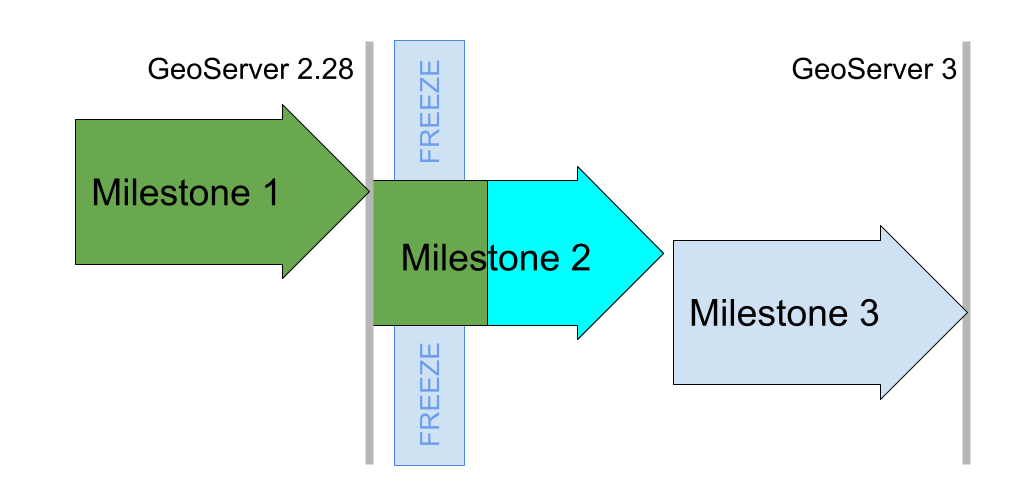
With the release of GeoServer 2.28.0 earlier this month Milestone 1 is officially accomplished. Our goal for Milestone 1 was to clear the decks of as much work as possible before performing the big migration to Spring Framework 6. The key objectives met are:
Replace the image processing engine, updating from Java Advanced Imaging 1.1.3 to Eclipse ImageN 0.9.0 which was released for the occasion. This is a major technical accomplishment, years in the making, combining the Oracle donation of the JAI codebase with all the work done by GeoSolutions on JAI-Ext.
The Eclipse ImageN integration was completed for the release of GeoServer 2.28.0. This activity was directly sponsored by the Office of Public Works.
Java 17 LTS minimum, and related maven “bill-of-materials” improvements, making it easier to manage the vast quantity of updates planned for Milestone 2.
Replacement for GeoServer OAuth2 support with a new OAuth2 Open ID Connect module is available to try out today and has been tested (and documented) with Google, GitHub, Microsoft Azure and Keycloak authentication providers. A really nice accomplishment is integration testing with KeyCloak (using test containers) clearing the way for this to be a supported extension in the future. There of course remains work to do, with a list of functionalities to complete by the end of the project.
Milestone 1 was completed a few weeks behind schedule, and we are really happy with the result. Eclipse ImageN is now available to the public and included in GeoServer 2.28.0 for widespread use.
GeoSolutions hosted the Milestone 2 code sprint in mid October, arranging perfect weather 🌧️ for a productive indoor gathering.
Prior to the code sprint we performed a code-freeze across five projects, putting external work on hold to allow the team assembled in person to focus. With the path cleared OpenRewrite migrations were performed for JakartaEE, Spring 6.2, Spring Security 6.5, and Wicket 10.
This was followed by manual fixing to get each section to first compile, then pass tests, satisfy the quality assurance checks, and finally to run.
The initial steps went smoothly for ImageIO-Ext and GeoTools. The GeoTools migration took some time out to work on Elasticsearch testing, and updating the http client library to use the same version as the other projects.
For GeoServer careful work was required by the whole team, working module by module. Interesting challenges included:
The embedded web applications (GeoWebCache, MapFishPrint and GeoFence) took considerably more work. GeoWebCache in particular was deeply affected by the URL mapper changes, struggling to resolve workspaces and layers when integrated with GeoServer. GeoFence remains in progress and is scheduled to be addressed in Milestone 3.
The code sprint was very successful, it was really effective to have a team meet in person allowing modules to be worked on in parallel. This places the GeoServer 3 project on track and we are confident in meeting the community March release schedule.
We would like to thank all the organizations who have sponsored the GeoServer 3 Crowdfunding activity. We appreciate your trust and recognize your dedication to the GeoServer project.
GeoServer 3 is supported by the following organisation:
![]()
![]()
![]()
![]()
![]()
![]()

![]()
![]()
![]()


![]()
![]()

![]()

![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Individual donations: Abhijit Gujar, Hennessy Becerra, Ivana Ivanova, John Bryant, Jason Horning, Peter Smythe, Sajjadul Islam, Sebastiano Meier, Stefan Overkamp.
For more information visit the GeoServer 3 Crowdfunding page which provides an overview of the activity as a whole.


Reinder shared this pic with us – “at Van Piere bookshop in Eindhoven, the Netherlands. Oh – and how about the ‘map bag’ …?

En el marco de MundoGEO Connect 2026, se organizó el pasado 29 de octubre el webinar Suite gvSIG – la plataforma en software libre de gestión territorial.
En él se presentaron algunas de las últimas novedades de la plataforma gvSIG Online, integración con IA y casos de uso. Os traemos la grabación de la ponencia:

Esta charla forma parte de una serie de eventos geoespaciales que se desarrollan dentro de la Semana Geoespacial y son previas a la conferencia IDE (Infraestructura de Datos Geoespaciales) de Chile, que se celebrará el 4 de noviembre de 2025.
Este webinar, en el que participaron casi sesenta (60) asistentes, fue impartido por Ariel Anthieni, CEO de Kan Territory & IT y presidente de Geolibres Argentina, junto con Carmen Díez, Técnica SIG de Urbanismo, y Carlos López Quintanilla, CEO de PSIG, ambos pertenecientes a la junta directiva de la Asociación QGIS España, encargados de la Presidencia y Tesorería, respectivamente.

Participantes de la charla virtual IDE Chile.
Tras la presentación de la agenda y los objetivos de la charla, centrada en las actualizaciones de QGIS y su comunidad, se habló sobre la creación y contribución al proyecto QGIS, tanto de la Asociación QGIS España como de QGIS Argentina, y se mencionó cómo colaborar con sus comunidades de usuarios y desarrolladores.
También se abordó el tema del roadmap entre QGIS 3 y QGIS 4, y se realizó una demostración en vivo del uso de QGIS con datos de la IDE Chile, incluyendo actuaciones como: cargar capas, simbolizar, etiquetar, seleccionar por expresión, hacer composiciones y geoprocesos, y utilizar complementos.

Demostración práctica con datos de la IDE Chile en QGIS.
Se puede acceder tanto al vídeo de la charla virtual, disponible en el canal de YouTube de IDE Chile, como a la presentación alojada en la plataforma de la Asociación QGIS España.
En ellos puedes encontrar información sobre la creación de la Asociación QGIS España en 2018 para apoyar el desarrollo de QGIS, que ahora cuenta con casi 100 miembros, incluyendo numerosas grandes y pequeñas empresas, y cómo contribuye económica y técnicamente al proyecto QGIS.
Se destaca la importancia de la divulgación del uso de QGIS y la resolución de dudas de los usuarios, mencionándose la posibilidad de asociarse a través del formulario de inscripción en su web.
También se ofrece información sobre objetivos, estatutos y cómo contactar con la Asociación y colaborar con QGIS:
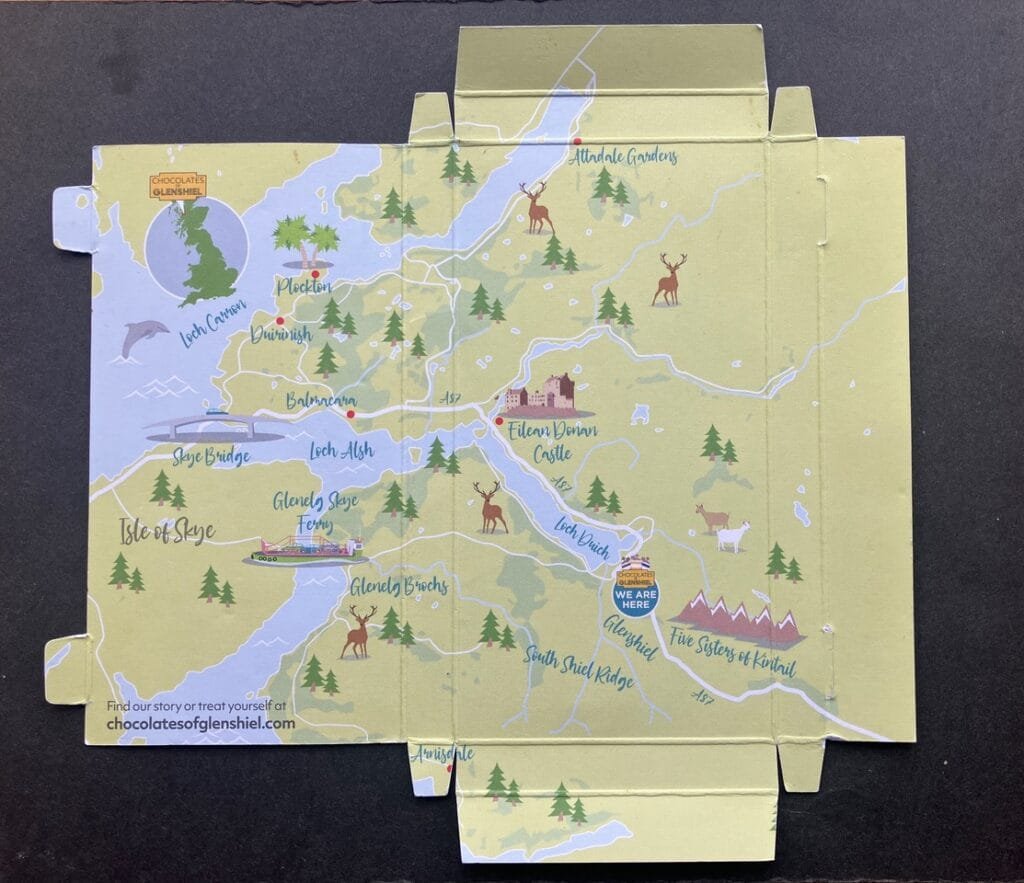
Keith Hodgson sent us this pic of Glenshiels Chocolate along with this lovely message:
“Greetings Friends of maps
On a recent camping holiday in Scotland, we stayed at Glenshiels. A local small firm made chocolate with an outlet and cafe attached to the small building that housed the works. Being a lover of good, dark chocolate, several bars were bought. Once eaten, the inside of the packaging revealed a bonus in the form of a map of the area. Something to share after the delicious chocolate.
Love your site, thanks for all you do keeping it going.”
And our thanks to you Keith for your kind words, a bar of that chocolate would also be appreciated!


Mark Iliffe is running the New York marathon today. Here he is with his participant number. If you are an armchair marathon follower, look out for him.
Good luck Mark

Reinder spotted this plan at the municipal archives in The Hague: in English it says ‘Map of the good city’ Den Haag.

The conversation around Looking for better ways to convert between QGIS VectorLayer and (Geo)DataFrame is continuing over at https://fosstodon.org/@underdarkGIS/115442614331293320
What I’ve learned so far:
Exciting times for spatial data science tooling 

Kenwood is a stately home and park near to where I live. They have a Halloween event on at the moment with an array of displays and activities around the park.

This isn’t normally a graveyard

El Ayuntamiento de Cullera ha dado un paso más en su proceso de transformación digital con la incorporación de un panel táctil interactivo en el cementerio municipal, que permite a cualquier persona localizar fácilmente la ubicación exacta de sus familiares y allegados.
Esta nueva herramienta se basa en la plataforma gvSIG Online, desarrollada por SCOLAB, y forma parte de un proyecto de digitalización que utiliza tecnologías geoespaciales para mejorar la gestión y el acceso a la información de todo el municipio.
Gracias a esta solución, el consistorio dispone de un sistema cartográfico completo del cementerio, que permite mantener actualizada la información de las parcelas y ofrecer a la ciudadanía una consulta ágil, intuitiva y accesible mediante el nuevo panel instalado en la entrada del recinto.
Esta misma aplicación está instalada en otros ayuntamientos que han confiado en gvSIG como solución para la gestión de su información espacial, como el Ayuntamiento de Albacete y el de Onda.
El proyecto ha sido financiado con fondos europeos Next Generation en el marco del Plan de Transformación Digital del Ayuntamiento de Cullera, demostrando cómo las tecnologías abiertas y geoespaciales pueden aplicarse a servicios municipales muy diversos, mejorando la atención ciudadana y optimizando la gestión pública.
La noticia ha sido recogida por la prensa generalista:
Las Provincias: https://www.lasprovincias.es/ribera-costera/cullera-instala-pantalla-digital-cementerio-localizar-familiares-20251030152048-nt_amp.html
Este viernes 17 de octubre estuvimos de cumpleaños. Agresta celebraba sus 25 años y, por suerte, teníamos invitación. Agresta es un nombre que nos acompaña desde hace tiempo, pero que tuvimos la oportunidad de desvirtualizar en el 9º Congreso Forestal celebrado en Gijón este 2025. Es una cooperativa del sector forestal, y precisamente sobre esas dos ideas —cooperativismo y sector forestal— giró el evento del viernes.
La primera parte estuvo dedicada al cooperativismo. Agresta es una cooperativa orgullosa de serlo, y organizó una mesa redonda con varias invitadas del mundo cooperativo. Hablaron sobre la importancia del cooperativismo, sus fortalezas y su situación actual, tanto a nivel nacional como internacional. Nos quedamos con esta maravilla:
 Cuenta de Instagram de guapa.lista.y.cooperativista
Cuenta de Instagram de guapa.lista.y.cooperativistaMarina Vargas, experta en autoconsumo colectivo y creadora de contenidos en Ecooo, es la cara detrás del perfil de Instagram guapa.lista.y.cooperativista, un espacio que transmite los valores cooperativistas con humor, cercanía y mucha energía.
Después llegó la segunda mesa, centrada en el sector forestal, donde se debatió sobre el presente y el futuro del sector.
El cambio entre ambas mesas estuvo amenizado por un par de momentos de RAMP, algo así como un RAP “ramplón” —maravillos por cierto—.
La guinda del pastel fue la presentación de ForesmapIA, una herramienta que busca obtener información forestal de manera dinámica a partir de diferentes fuentes de datos y del uso de inteligencia artificial. Fueron los mismo socios de la cooperativa quienes nos mostraron el recorrido de esta herramienta y sus planes de futuro.
Para finalizar, foto de grupo y brindis (con picoteo) que nos permitió compartir un rato con la gente de Agresta.
Para nosotros fue una jornada muy agradable, donde conocimos una versión diferente de Agresta. El cariño con el que organizaron la jornada, cuidando hasta el último detalle, hizo que nos fuéramos de allí con mucha energía y orgullosos de formar parte de esta red de cooperativas que creemos en una manera diferente de hacer negocios.
Agresta, muchas felicidades y ¡nos vemos en los montes!
 Como no podía ser de otra manera, el regalo a tono con el resto del evento.
Como no podía ser de otra manera, el regalo a tono con el resto del evento.

We love a floor map and Ken spotted this beauty with flight routes at Salt Lake City Airport

This is a bugfix and maintenance release. While there are no new features or API changes, this release includes important bug fixes, documentation improvements, and minor enhancements across datasets, models, and testing.
This release is made possible thanks to the following contributors:

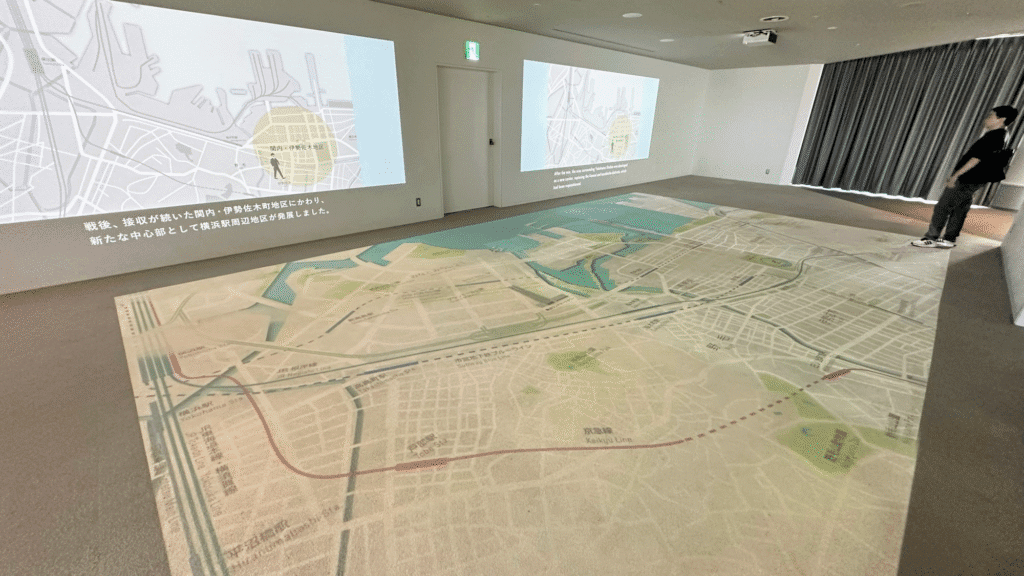
Another floor map, this time from Kenneth Wong “a giant map of Yokohama on Yokohama Landmark Tower’s observation deck
An enormous map spreading out the floor is always a cool thing to me” – I agree
Hola a todos.
Últimamente, las redes sociales y las plataformas de prompts se han llenado de una especie de mercado mágico. Un sitio como Promptfy promete cientos de “recetas listas para usar” que, con solo copiar y pegar, resuelven problemas complejos de IA. Y no hablemos de LinkedIn o X, donde un post con un “prompt infalible” para generar código Python acumula likes como si fuera “el santo grial”. Entiendo el atractivo.En un mundo donde se valora cada vez mas el producir mas en menos tiempo ¿quién no querría un atajo directo a la productividad?
Pero aquí va mi preocupación, surgida de años observando cómo se integran las herramientas en el flujo de desarrollo. ¿Y si estos atajos están formando operadores de IA en lugar de desarrolladores reales? Especialmente para los juniors, que entran en este ecosistema con ojos brillantes pero sin el bagaje para cuestionar. Copiar un prompt puede ser un salvavidas temporal. El problema surge cuando se convierte en muleta permanente. Puedes estamparte profesionalmente al primer tropiezo con un caso no cubierto por la receta.
Imaginad a un cocinero que sigue una receta al pie de la letra. Con ingredientes frescos y el horno a punto, sale un plato decente. Ahora, cambiad el aceite por mantequilla rancia o el horno se apaga a mitad. ¿Qué hace? Si solo sabe recitar pasos, está perdido. Ese es el junior que copia prompts. Un cocinero eficiente en condiciones ideales, pero sin el instinto de un chef para improvisar.
El problema es que, con el tiempo, dejas de entrenar tus habilidades que de verdad importan
He visto esto antes. Recordad el salto de C a Java. El Garbage Collector abstrajo la gestión de memoria. Juniors producían código rápido sin malloc ni free. Pero el senior que diagnostica un OutOfMemoryError en un sistema con millones de objetos sabe que el conocimiento fundamental no se abstrae. Las recetas de prompts son el nuevo GC. Aceleran el 80% fácil. En el 20% duro te dejan expuesto.
No pido renunciar a las recetas. Úsalas como punto de partida, no como destino. La alternativa es tratar el prompting como ingeniería. Tenemos que diseñar instrucciones, no solo escribirlas. Os detallo mi proceso.
Cuando me enfrento a un problema, lo primero no es escribir el prompt. Diseño la pregunta que lo genera.
Prueba esto en un problema pequeño. Verás cómo el “baile” revela capas que una receta ignora. Y, de paso, construyes ese mapa mental que te hace senior.
La productividad no nace de una biblioteca de prompts copiados. Nace de saber construir el prompt adecuado para un problema nuevo. Ese es el valor que justifica tu asiento en la mesa de seniors.
A los mentores y seniors. No demos pescados envueltos en prompts bonitos. Enseñemos a pescar. Con meta-preguntas, validaciones y síntesis. Guiemos a los juniors hacia la maestría, no la dependencia.
A los juniors. Resistid la tentación del atajo. El camino lento de entender el “porqué” de una instrucción os hará infinitamente más valiosos que el que solo copia y pega. Preguntad, iterad, cuestionad. El LLM es herramienta. Vosotros, arquitectos.
Al final, el objetivo no es coleccionar respuestas. Es dominar el arte de hacer preguntas.
Si os resuena, probad el método en vuestro próximo reto. Y contadme en los comentarios ¿habéis caído en la trampa de las recetas? ¿Qué os sacó de ahí?
Un saludo

Ken spotted this carton of beer in his local supermarket.

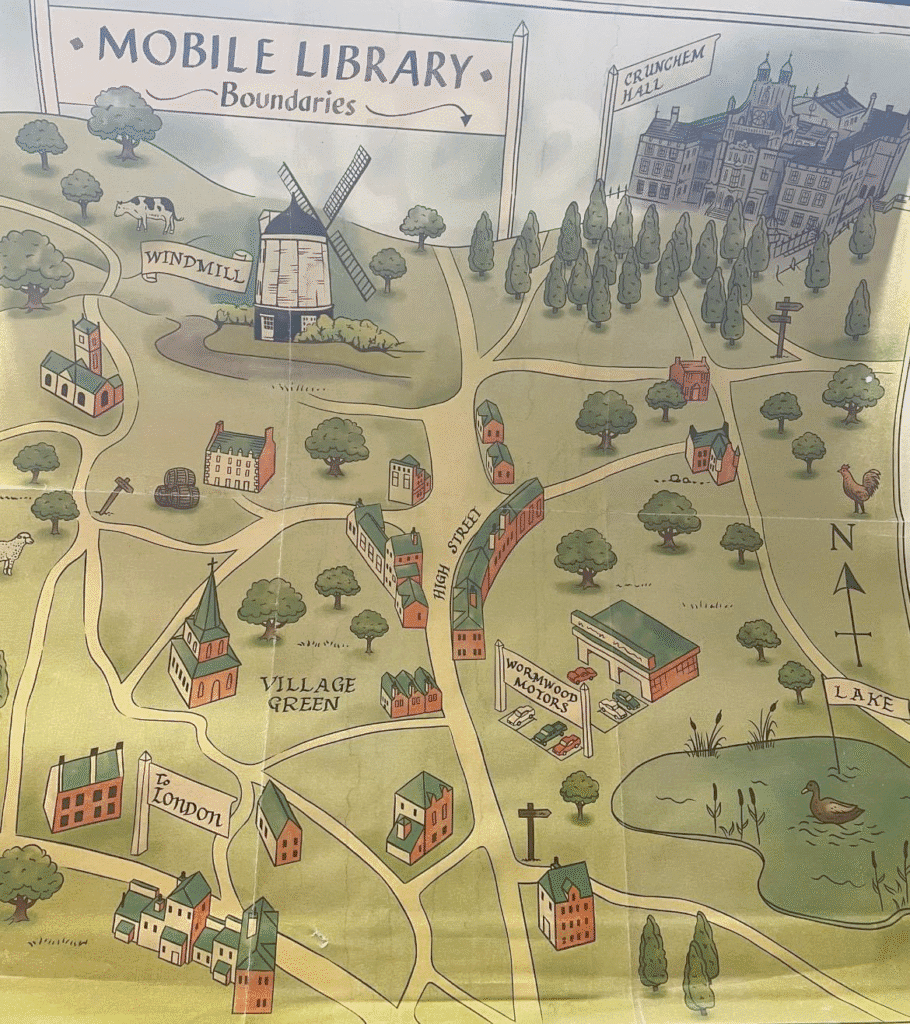
Clare spotted this Mobile Library Map when rewatching Matilda the Musical. “Just rewatched Matilda the Musical and spotted the map
inside the Mobile Library when Matilda rushes out. It was acquired on pinboards from a reuse site – from the Studios!!
Amazing to think of all the art created for film and TV that may only get 0.1s on screen”
Plugin developers who want to use (Geo)Pandas-based functionality in their plugins regularly face the challenge of converting QGIS vector layers to (Geo)DataFrames. There is currently no built-in convenience function.
In Trajectools, so far, I have been performing the conversion manually, looping through all features and taking care of tricky column types, such as datetimes and geometries:
def df_from_layer_trajectools(layer,time_field_name="t"):
# Original Trajectools 2.7 version
names = [field.name() for field in layer.fields()]
data = []
for feature in layer.getFeatures():
my_dict = {}
for i, a in enumerate(feature.attributes()):
if names[i] == time_field_name and isinstance(a, QDateTime):
a = a.toPyDateTime()
my_dict[names[i]] = a
pt = feature.geometry().asPoint()
my_dict["geom_x"] = pt.x()
my_dict["geom_y"] = pt.y()
data.append(my_dict)
df = pd.DataFrame(data)
return df
It works (mostly), but it’s far from fast. For the 25 million Geolife points, it takes 4 minutes:

In an attempt to speed-up (and make the conversion more robust, e.g. regarding datetime/timezone conversion and null values), I’ve spent some time at SDSL2025 with Joris Van den Bossche trying a workaround that writes the QGIS layer to an Arrow file and then reads that file with pyogrio:
def gdf_from_layer_arrow(layer):
# SDSL2025 version
with tempfile.TemporaryDirectory() as tmpdirname:
path = os.path.join(tmpdirname, "data.arrow")
options = QgsVectorFileWriter.SaveVectorOptions()
options.actionOnExistingFile = QgsVectorFileWriter.CreateOrOverwriteFile
options.layerName = 'data'
options.driverName = "arrow"
QgsVectorFileWriter.writeAsVectorFormatV3(
layer, path, QgsProject.instance().transformContext(), options
)
meta, table = pyogrio.read_arrow(path)
gdf = gpd.GeoDataFrame.from_arrow(table)
return gdf
Not only do we get a GeoDataFrame in return, this also runs in half the time, i.e. in 2 minutes instead of 4:

Switching to this approach will require adding pyogrio to the plugin dependencies. Looks like it could be worth it.
We also discussed another alternative: It would be faster to read the vector layer data source directly, in case it is a supported file format. However, this means we’d need separate handling for other input layers.
There’s also the issue of supporting the Processing feature that allows users to run the algorithm only on the selected features because selected features are only exposed through QgsProcessingParameterFeatureSource (and not through QgsProcessingParameterVectorLayer). Maybe the Export Selected Features algorithm can cover this case but it will export an empty layer if there is no selection.
Are you aware of any other / better ways to approach this issue? Any pointers are appreciated.
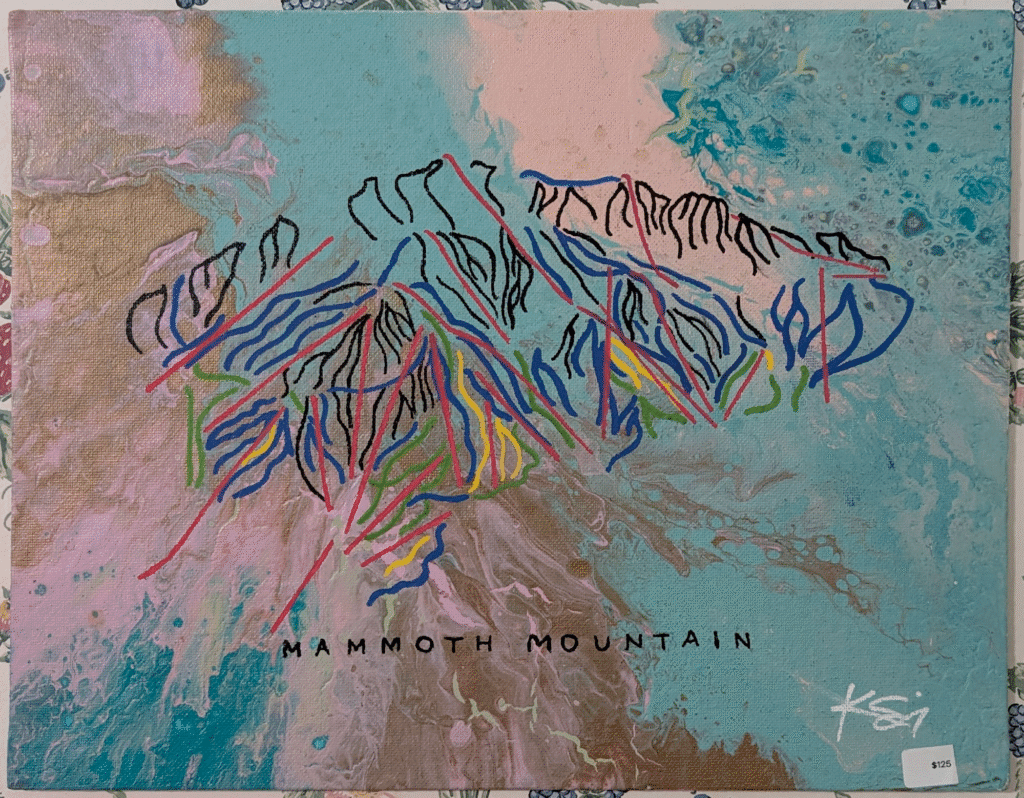
Ken shared this abstract Mammoth mountain ski trail map – $125 seems a fair price but you couldn’t really take it on the slopes with you.

I spotted this piece by Stephen Graham in a local gallery. I’m not sure that I’d like to have it hanging in my home but then I feel out of love with pop art nearly fifty years ago! I do like the way my photo picks up the old buildings reflected in the gallery window, almost the counterpoint.

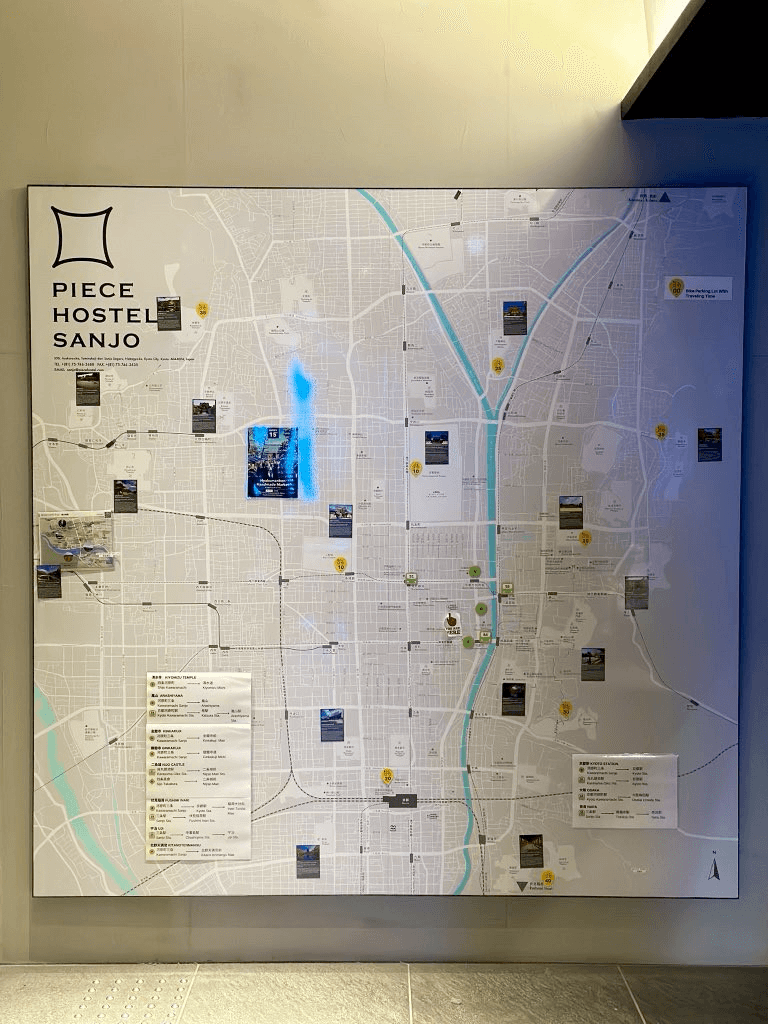
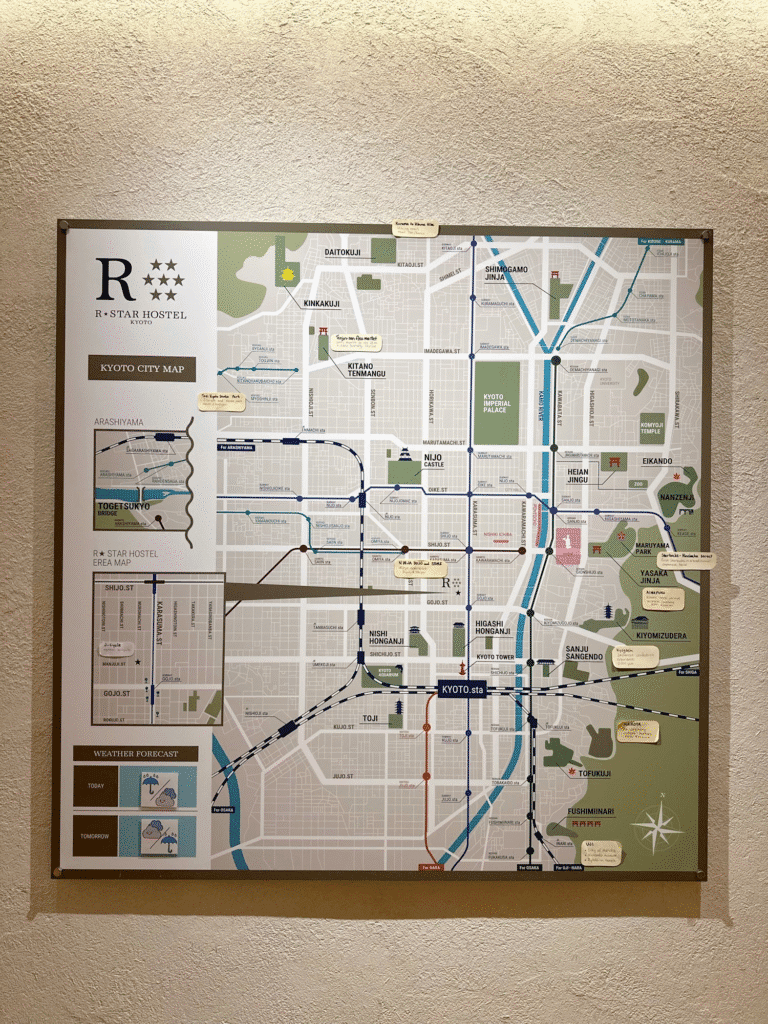
Kenneth Wong stayed in Kyoto last year and shared these maps from two different hotels. He commented “Two hostels I stayed in Kyoto last Nov. Both have a gigantic city map hung near reception. Comparing the differences of their approaches to map the town and show the tourist spots would be a great cartography article” I am a R-Star fan.

Nach etwa 15 Jahren Mitgliedschaft im informellen Interlis-Kernteam und zwei Jahren in der offiziellen Nachfolgegruppe SOGI GGMM, habe ich mich kürzlich aus diesem Interlis-Gremium zurückgezogen. Der Grund liegt hauptsächlich darin, dass meine Prioritäten in der Geo-Normierung in Themen liegen, die in dieser Arbeitsgruppe nur peripher abgedeckt werden. Nichts destotrotz möchte ich aus diesem Anlass meine Gedanken zur Vergangenheit und Zukunft von Interlis festhalten.
Another one from Cartonaut, does anyone know who the artist is?

by Jody Garnett (noreply@blogger.com) at October 22, 2025 12:08 PM
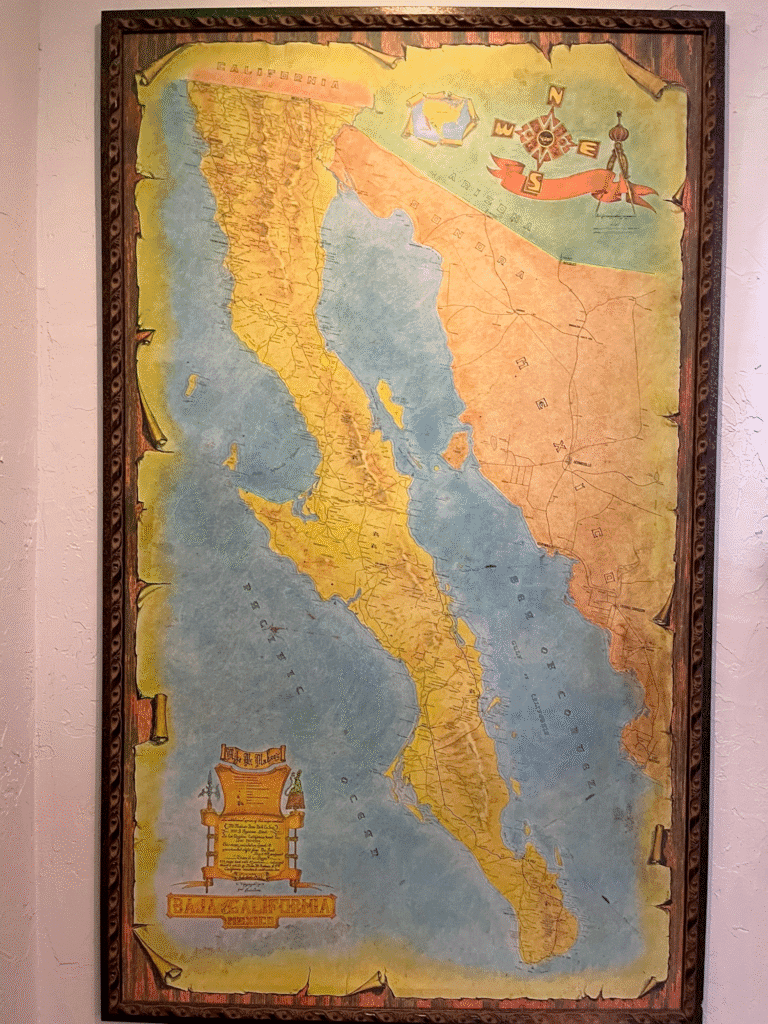
Charles Robbins shared this